 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Self-supervised Pre-fine-tuned Transformer Fusion for Better Intelligent Transportation Detection
Oct 17, 2023Intelligent transportation system combines advanced information technology to provide intelligent services such as monitoring, detection, and early warning for modern transportation. Intelligent transportation detection is the cornerstone of many intelligent traffic services by identifying task targets through object detection methods. However existing detection methods in intelligent transportation are limited by two aspects. First, there is a difference between the model knowledge pre-trained on large-scale datasets and the knowledge required for target task. Second, most detection models follow the pattern of single-source learning, which limits the learning ability. To address these problems, we propose a Multi Self-supervised Pre-fine-tuned Transformer Fusion (MSPTF) network, consisting of two steps: unsupervised pre-fine-tune domain knowledge learning and multi-model fusion target task learning. In the first step, we introduced self-supervised learning methods into transformer model pre-fine-tune which could reduce data costs and alleviate the knowledge gap between pre-trained model and target task. In the second step, we take feature information differences between different model architectures and different pre-fine-tune tasks into account and propose Multi-model Semantic Consistency Cross-attention Fusion (MSCCF) network to combine different transformer model features by considering channel semantic consistency and feature vector semantic consistency, which obtain more complete and proper fusion features for detection task. We experimented the proposed method on vehicle recognition dataset and road disease detection dataset and achieved 1.1%, 5.5%, 4.2% improvement compared with baseline and 0.7%, 1.8%, 1.7% compared with sota, which proved the effectiveness of our method.
Road Disease Detection based on Latent Domain Background Feature Separation and Suppression
Sep 14, 2023Road disease detection is challenging due to the the small proportion of road damage in target region and the diverse background,which introduce lots of domain information.Besides, disease categories have high similarity,makes the detection more difficult. In this paper, we propose a new LDBFSS(Latent Domain Background Feature Separation and Suppression) network which could perform background information separation and suppression without domain supervision and contrastive enhancement of object features.We combine our LDBFSS network with YOLOv5 model to enhance disease features for better road disease detection. As the components of LDBFSS network, we first design a latent domain discovery module and a domain adversarial learning module to obtain pseudo domain labels through unsupervised method, guiding domain discriminator and model to train adversarially to suppress background information. In addition, we introduce a contrastive learning module and design k-instance contrastive loss, optimize the disease feature representation by increasing the inter-class distance and reducing the intra-class distance for object features. We conducted experiments on two road disease detection datasets, GRDDC and CNRDD, and compared with other models,which show an increase of nearly 4% on GRDDC dataset compared with optimal model, and an increase of 4.6% on CNRDD dataset. Experimental results prove the effectiveness and superiority of our model.
Integrating GAN and Texture Synthesis for Enhanced Road Damage Detection
Sep 13, 2023



In the domain of traffic safety and road maintenance, precise detection of road damage is crucial for ensuring safe driving and prolonging road durability. However, current methods often fall short due to limited data. Prior attempts have used Generative Adversarial Networks to generate damage with diverse shapes and manually integrate it into appropriate positions. However, the problem has not been well explored and is faced with two challenges. First, they only enrich the location and shape of damage while neglect the diversity of severity levels, and the realism still needs further improvement. Second, they require a significant amount of manual effort. To address these challenges, we propose an innovative approach. In addition to using GAN to generate damage with various shapes, we further employ texture synthesis techniques to extract road textures. These two elements are then mixed with different weights, allowing us to control the severity of the synthesized damage, which are then embedded back into the original images via Poisson blending. Our method ensures both richness of damage severity and a better alignment with the background. To save labor costs, we leverage structural similarity for automated sample selection during embedding. Each augmented data of an original image contains versions with varying severity levels. We implement a straightforward screening strategy to mitigate distribution drift. Experiments are conducted on a public road damage dataset. The proposed method not only eliminates the need for manual labor but also achieves remarkable enhancements, improving the mAP by 4.1% and the F1-score by 4.5%.
MFL-YOLO: An Object Detection Model for Damaged Traffic Signs
Sep 13, 2023



Traffic signs are important facilities to ensure traffic safety and smooth flow, but may be damaged due to many reasons, which poses a great safety hazard. Therefore, it is important to study a method to detect damaged traffic signs. Existing object detection techniques for damaged traffic signs are still absent. Since damaged traffic signs are closer in appearance to normal ones, it is difficult to capture the detailed local damage features of damaged traffic signs using traditional object detection methods. In this paper, we propose an improved object detection method based on YOLOv5s, namely MFL-YOLO (Mutual Feature Levels Loss enhanced YOLO). We designed a simple cross-level loss function so that each level of the model has its own role, which is beneficial for the model to be able to learn more diverse features and improve the fine granularity. The method can be applied as a plug-and-play module and it does not increase the structural complexity or the computational complexity while improving the accuracy. We also replaced the traditional convolution and CSP with the GSConv and VoVGSCSP in the neck of YOLOv5s to reduce the scale and computational complexity. Compared with YOLOv5s, our MFL-YOLO improves 4.3 and 5.1 in F1 scores and mAP, while reducing the FLOPs by 8.9%. The Grad-CAM heat map visualization shows that our model can better focus on the local details of the damaged traffic signs. In addition, we also conducted experiments on CCTSDB2021 and TT100K to further validate the generalization of our model.
Fine-tuning ERNIE for chest abnormal imaging signs extraction
Nov 08, 2020


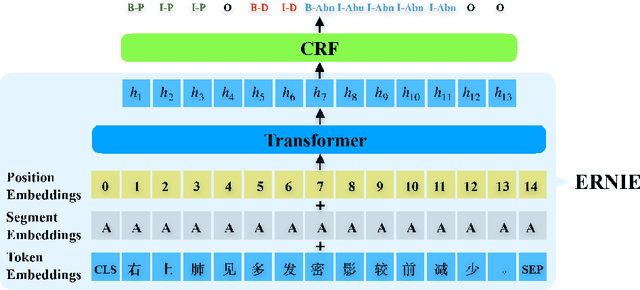
Chest imaging reports describe the results of chest radiography procedures. Automatic extraction of abnormal imaging signs from chest imaging reports has a pivotal role in clinical research and a wide range of downstream medical tasks. However, there are few studies on information extraction from Chinese chest imaging reports. In this paper, we formulate chest abnormal imaging sign extraction as a sequence tagging and matching problem. On this basis, we propose a transferred abnormal imaging signs extractor with pretrained ERNIE as the backbone, named EASON (fine-tuning ERNIE with CRF for Abnormal Signs ExtractiON), which can address the problem of data insufficiency. In addition, to assign the attributes (the body part and degree) to corresponding abnormal imaging signs from the results of the sequence tagging model, we design a simple but effective tag2relation algorithm based on the nature of chest imaging report text. We evaluate our method on the corpus provided by a medical big data company, and the experimental results demonstrate that our method achieves significant and consistent improvement compared to other baselines.
* 30 pages, 5 figures, 8 tables
Causality Extraction based on Self-Attentive BiLSTM-CRF with Transferred Embeddings
Apr 29, 2019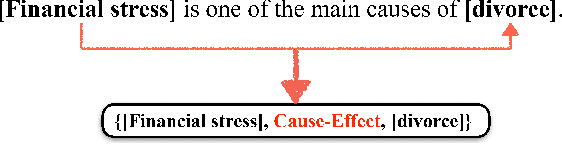


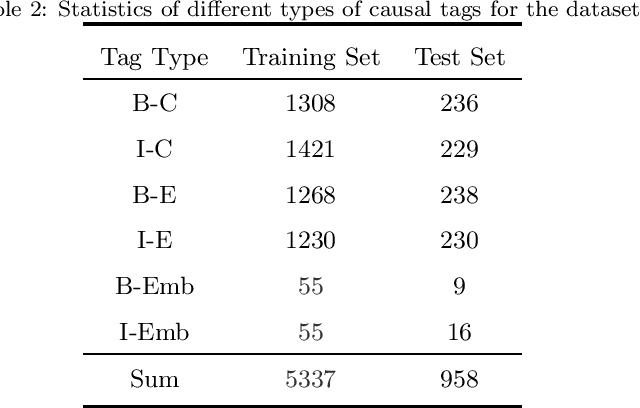
Causality extraction from natural language texts is a challenging open problem in artificial intelligence. Existing methods utilize patterns, constraints, and machine learning techniques to extract causality, heavily depend on domain knowledge and require considerable human efforts and time on feature engineering. In this paper, we formulate causality extraction as a sequence tagging problem based on a novel causality tagging scheme. On this basis, we propose a neural causality extractor with BiLSTM-CRF model as the backbone, named SCIFI (Self-Attentive BiLSTM-CRF with Flair Embeddings), which can directly extract Cause and Effect, without extracting candidate causal pairs and identifying their relations separately. To tackle the problem of data insufficiency, we transfer the contextual string embeddings, also known as Flair embeddings, which trained on a large corpus into our task. Besides, to improve the performance of causality extraction, we introduce the multi-head self-attention mechanism into SCIFI to learn the dependencies between causal words. We evaluate our method on a public dataset, and experimental results demonstrate that our method achieves significant and consistent improvement as compared to other baselines.