 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-to-Text Logic Jailbreak: Your Imagination can Help You Do Anything
Jul 01, 2024Large Visual Language Models (VLMs) such as GPT-4 have achieved remarkable success in generating comprehensive and nuanced responses, surpassing the capabilities of large language models. However, with the integration of visual inputs, new security concerns emerge, as malicious attackers can exploit multiple modalities to achieve their objectives. This has led to increasing attention on the vulnerabilities of VLMs to jailbreak. Most existing research focuses on generating adversarial images or nonsensical image collections to compromise these models. However, the challenge of leveraging meaningful images to produce targeted textual content using the VLMs' logical comprehension of images remains unexplored. In this paper, we explore the problem of logical jailbreak from meaningful images to text. To investigate this issue, we introduce a novel dataset designed to evaluate flowchart image jailbreak. Furthermore, we develop a framework for text-to-text jailbreak using VLMs. Finally, we conduct an extensive evaluation of the framework on GPT-4o and GPT-4-vision-preview, with jailbreak rates of 92.8% and 70.0%, respectively. Our research reveals significant vulnerabilities in current VLMs concerning image-to-text jailbreak. These findings underscore the need for a deeper examination of the security flaws in VLMs before their practical deployment.
Is the System Message Really Important to Jailbreaks in Large Language Models?
Feb 20, 2024The rapid evolution of Large Language Models (LLMs) has rendered them indispensable in modern society. While security measures are typically in place to align LLMs with human values prior to release, recent studies have unveiled a concerning phenomenon named "jailbreak." This term refers to the unexpected and potentially harmful responses generated by LLMs when prompted with malicious questions. Existing research focuses on generating jailbreak prompts but our study aim to answer a different question: Is the system message really important to jailbreak in LLMs? To address this question, we conducted experiments in a stable GPT version gpt-3.5-turbo-0613 to generated jailbreak prompts with varying system messages: short, long, and none. We discover that different system messages have distinct resistances to jailbreak by experiments. Additionally, we explore the transferability of jailbreak across LLMs. This finding underscores the significant impact system messages can have on mitigating LLMs jailbreak. To generate system messages that are more resistant to jailbreak prompts, we propose System Messages Evolutionary Algorithms (SMEA). Through SMEA, we can get robust system messages population that demonstrate up to 98.9% resistance against jailbreak prompts. Our research not only bolsters LLMs security but also raises the bar for jailbreak, fostering advancements in this field of study.
Causality Extraction based on Self-Attentive BiLSTM-CRF with Transferred Embeddings
Apr 29, 2019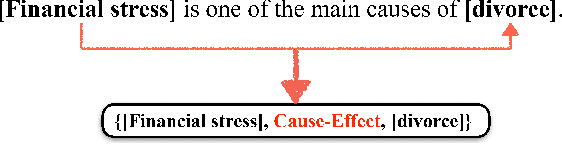


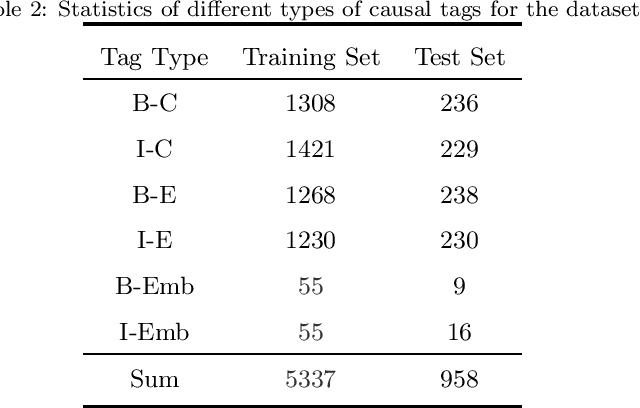
Causality extraction from natural language texts is a challenging open problem in artificial intelligence. Existing methods utilize patterns, constraints, and machine learning techniques to extract causality, heavily depend on domain knowledge and require considerable human efforts and time on feature engineering. In this paper, we formulate causality extraction as a sequence tagging problem based on a novel causality tagging scheme. On this basis, we propose a neural causality extractor with BiLSTM-CRF model as the backbone, named SCIFI (Self-Attentive BiLSTM-CRF with Flair Embeddings), which can directly extract Cause and Effect, without extracting candidate causal pairs and identifying their relations separately. To tackle the problem of data insufficiency, we transfer the contextual string embeddings, also known as Flair embeddings, which trained on a large corpus into our task. Besides, to improve the performance of causality extraction, we introduce the multi-head self-attention mechanism into SCIFI to learn the dependencies between causal words. We evaluate our method on a public dataset, and experimental results demonstrate that our method achieves significant and consistent improvement as compared to other baselines.