 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMAP: Single-Shot Multi-Person Absolute 3D Pose Estimation
Aug 26, 2020
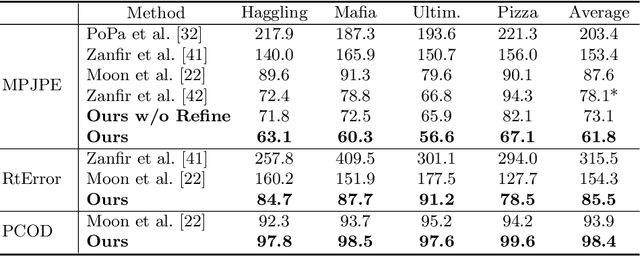
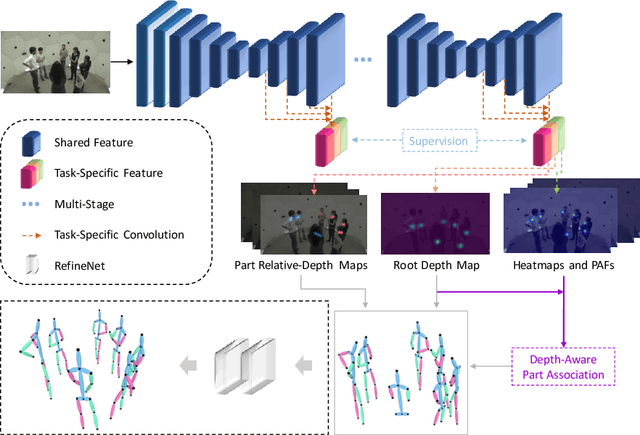
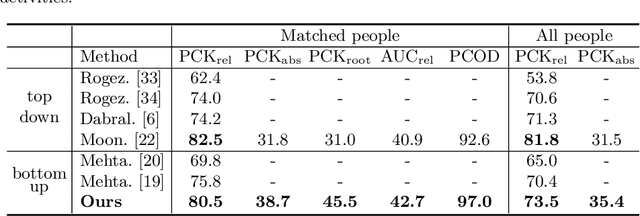
Recovering multi-person 3D poses with absolute scales from a single RGB image is a challenging problem due to the inherent depth and scale ambiguity from a single view. Addressing this ambiguity requires to aggregate various cues over the entire image, such as body sizes, scene layouts, and inter-person relationships. However, most previous methods adopt a top-down scheme that first performs 2D pose detection and then regresses the 3D pose and scale for each detected person individually, ignoring global contextual cues. In this paper, we propose a novel system that first regresses a set of 2.5D representations of body parts and then reconstructs the 3D absolute poses based on these 2.5D representations with a depth-aware part association algorithm. Such a single-shot bottom-up scheme allows the system to better learn and reason about the inter-person depth relationship, improving both 3D and 2D pose estimation. The experiments demonstrate that the proposed approach achieves the state-of-the-art performance on the CMU Panoptic and MuPoTS-3D datasets and is applicable to in-the-wild videos.