 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOV: The Original Vision Model for Optical Remote Sensing Image Understanding via Self-supervised Learning
Apr 10, 2022

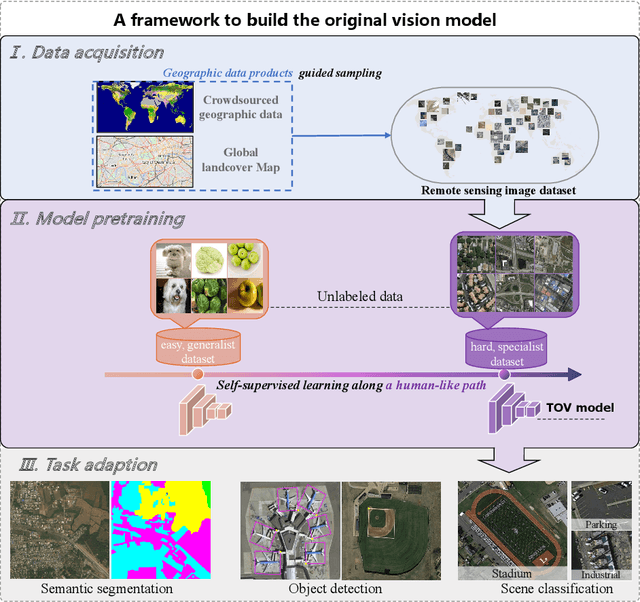

Do we on the right way for remote sensing image understanding (RSIU) by training models via supervised data-dependent and task-dependent way, instead of human vision in a label-free and task-independent way? We argue that a more desirable RSIU model should be trained with intrinsic structure from data rather that extrinsic human labels to realize generalizability across a wide range of RSIU tasks. According to this hypothesis, we proposed \textbf{T}he \textbf{O}riginal \textbf{V}ision model (TOV) in remote sensing filed. Trained by massive unlabeled optical data along a human-like self-supervised learning (SSL) path that is from general knowledge to specialized knowledge, TOV model can be easily adapted to various RSIU tasks, including scene classification, object detection, and semantic segmentation, and outperforms dominant ImageNet supervised pretrained method as well as two recently proposed SSL pretrained methods on majority of 12 publicly available benchmarks. Moreover, we analyze the influences of two key factors on the performance of building TOV model for RSIU, including the influence of using different data sampling methods and the selection of learning paths during self-supervised optimization. We believe that a general model which is trained by a label-free and task-independent way may be the next paradigm for RSIU and hope the insights distilled from this study can help to foster the development of an original vision model for RSIU.