 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlessemFlood21: Advancing Flood Analysis with a High-Resolution Georeferenced Dataset for Humanitarian Aid Support
Jul 06, 2024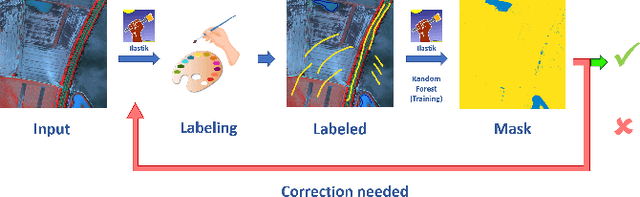
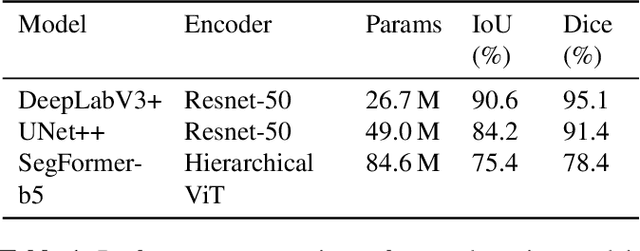


Floods are an increasingly common global threat, causing emergencies and severe damage to infrastructure. During crises, organisations such as the World Food Programme use remotely sensed imagery, typically obtained through drones, for rapid situational analysis to plan life-saving actions. Computer Vision tools are needed to support task force experts on-site in the evaluation of the imagery to improve their efficiency and to allocate resources strategically. We introduce the BlessemFlood21 dataset to stimulate research on efficient flood detection tools. The imagery was acquired during the 2021 Erftstadt-Blessem flooding event and consists of high-resolution and georeferenced RGB-NIR images. In the resulting RGB dataset, the images are supplemented with detailed water masks, obtained via a semi-supervised human-in-the-loop technique, where in particular the NIR information is leveraged to classify pixels as either water or non-water. We evaluate our dataset by training and testing established Deep Learning models for semantic segmentation. With BlessemFlood21 we provide labeled high-resolution RGB data and a baseline for further development of algorithmic solutions tailored to flood detection in RGB imagery.
Artificial and beneficial -- Exploiting artificial images for aerial vehicle detection
Apr 07, 2021

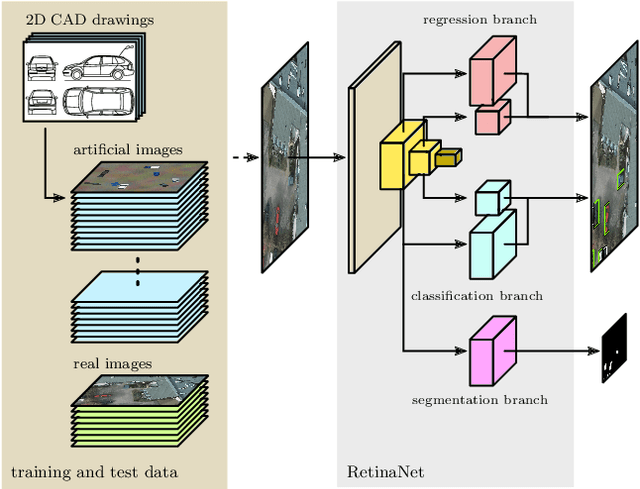

Object detection in aerial images is an important task in environmental, economic, and infrastructure-related tasks. One of the most prominent applications is the detection of vehicles, for which deep learning approaches are increasingly used. A major challenge in such approaches is the limited amount of data that arises, for example, when more specialized and rarer vehicles such as agricultural machinery or construction vehicles are to be detected. This lack of data contrasts with the enormous data hunger of deep learning methods in general and object recognition in particular. In this article, we address this issue in the context of the detection of road vehicles in aerial images. To overcome the lack of annotated data, we propose a generative approach that generates top-down images by overlaying artificial vehicles created from 2D CAD drawings on artificial or real backgrounds. Our experiments with a modified RetinaNet object detection network show that adding these images to small real-world datasets significantly improves detection performance. In cases of very limited or even no real-world images, we observe an improvement in average precision of up to 0.70 points. We address the remaining performance gap to real-world datasets by analyzing the effect of the image composition of background and objects and give insights into the importance of background.
* 14 pages, 13 figures, 4 tables