 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivileged Zero-Shot AutoML
Jun 25, 2021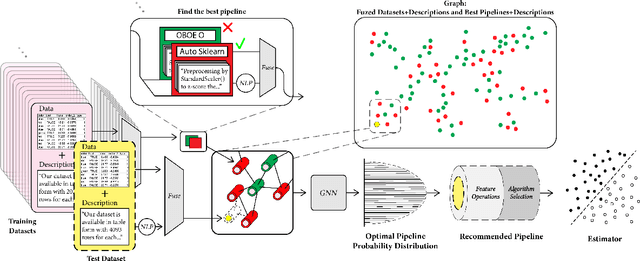
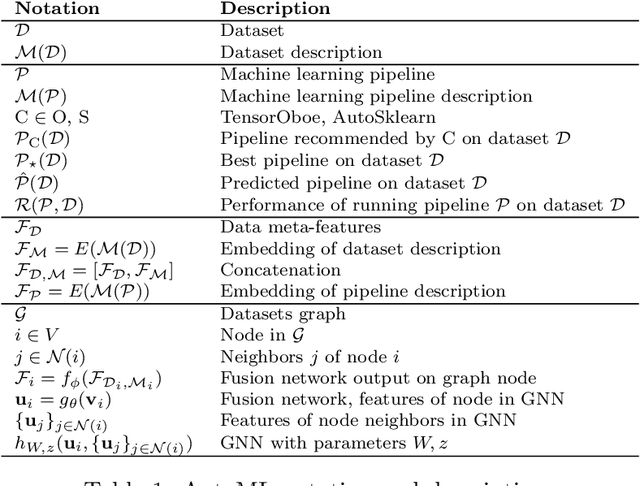
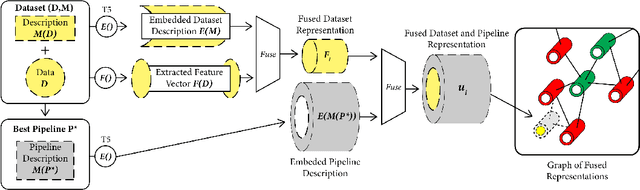
This work improves the quality of automated machine learning (AutoML) systems by using dataset and function descriptions while significantly decreasing computation time from minutes to milliseconds by using a zero-shot approach. Given a new dataset and a well-defined machine learning task, humans begin by reading a description of the dataset and documentation for the algorithms to be used. This work is the first to use these textual descriptions, which we call privileged information, for AutoML. We use a pre-trained Transformer model to process the privileged text and demonstrate that using this information improves AutoML performance. Thus, our approach leverages the progress of unsupervised representation learning in natural language processing to provide a significant boost to AutoML. We demonstrate that using only textual descriptions of the data and functions achieves reasonable classification performance, and adding textual descriptions to data meta-features improves classification across tabular datasets. To achieve zero-shot AutoML we train a graph neural network with these description embeddings and the data meta-features. Each node represents a training dataset, which we use to predict the best machine learning pipeline for a new test dataset in a zero-shot fashion. Our zero-shot approach rapidly predicts a high-quality pipeline for a supervised learning task and dataset. In contrast, most AutoML systems require tens or hundreds of pipeline evaluations. We show that zero-shot AutoML reduces running and prediction times from minutes to milliseconds, consistently across datasets. By speeding up AutoML by orders of magnitude this work demonstrates real-time AutoML.
Image2Reverb: Cross-Modal Reverb Impulse Response Synthesis
Mar 26, 2021
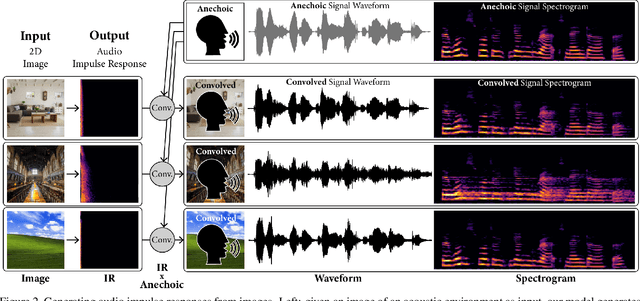
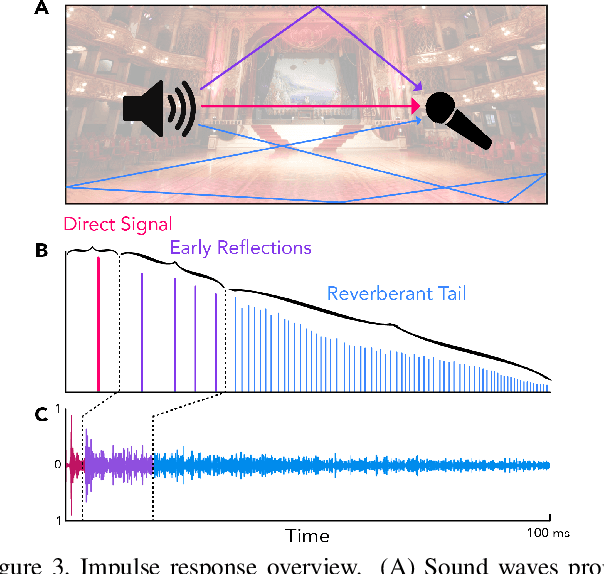
Measuring the acoustic characteristics of a space is often done by capturing its impulse response (IR), a representation of how a full-range stimulus sound excites it. This is the first work that generates an IR from a single image, which we call Image2Reverb. This IR is then applied to other signals using convolution, simulating the reverberant characteristics of the space shown in the image. Recording these IRs is both time-intensive and expensive, and often infeasible for inaccessible locations. We use an end-to-end neural network architecture to generate plausible audio impulse responses from single images of acoustic environments. We evaluate our method both by comparisons to ground truth data and by human expert evaluation. We demonstrate our approach by generating plausible impulse responses from diverse settings and formats including well known places, musical halls, rooms in paintings, images from animations and computer games, synthetic environments generated from text, panoramic images, and video conference backgrounds.