 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffGuard: Text-Based Safety Checker for Diffusion Models
Nov 25, 2024Recent advances in Diffusion Models have enabled the generation of images from text, with powerful closed-source models like DALL-E and Midjourney leading the way. However, open-source alternatives, such as StabilityAI's Stable Diffusion, offer comparable capabilities. These open-source models, hosted on Hugging Face, come equipped with ethical filter protections designed to prevent the generation of explicit images. This paper reveals first their limitations and then presents a novel text-based safety filter that outperforms existing solutions. Our research is driven by the critical need to address the misuse of AI-generated content, especially in the context of information warfare. DiffGuard enhances filtering efficacy, achieving a performance that surpasses the best existing filters by over 14%.
Causal discovery for time series with constraint-based model and PMIME measure
May 31, 2023Causality defines the relationship between cause and effect. In multivariate time series field, this notion allows to characterize the links between several time series considering temporal lags. These phenomena are particularly important in medicine to analyze the effect of a drug for example, in manufacturing to detect the causes of an anomaly in a complex system or in social sciences... Most of the time, studying these complex systems is made through correlation only. But correlation can lead to spurious relationships. To circumvent this problem, we present in this paper a novel approach for discovering causality in time series data that combines a causal discovery algorithm with an information theoretic-based measure. Hence the proposed method allows inferring both linear and non-linear relationships and building the underlying causal graph. We evaluate the performance of our approach on several simulated data sets, showing promising results.
A New Approach for Explainable Multiple Organ Annotation with Few Data
Dec 30, 2019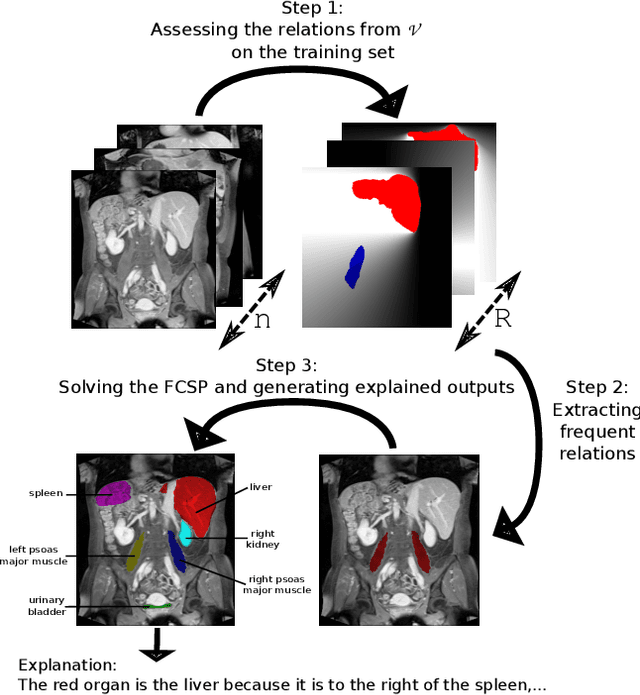
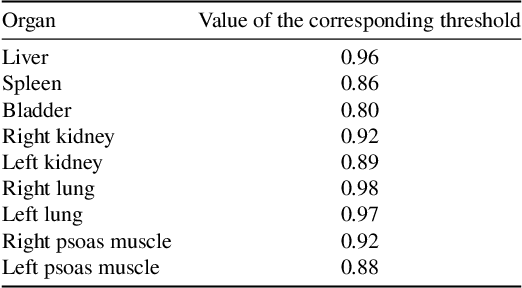

Despite the recent successes of deep learning, such models are still far from some human abilities like learning from few examples, reasoning and explaining decisions. In this paper, we focus on organ annotation in medical images and we introduce a reasoning framework that is based on learning fuzzy relations on a small dataset for generating explanations. Given a catalogue of relations, it efficiently induces the most relevant relations and combines them for building constraints in order to both solve the organ annotation task and generate explanations. We test our approach on a publicly available dataset of medical images where several organs are already segmented. A demonstration of our model is proposed with an example of explained annotations. It was trained on a small training set containing as few as a couple of examples.
Sim-to-Real Domain Adaptation For High Energy Physics
Dec 17, 2019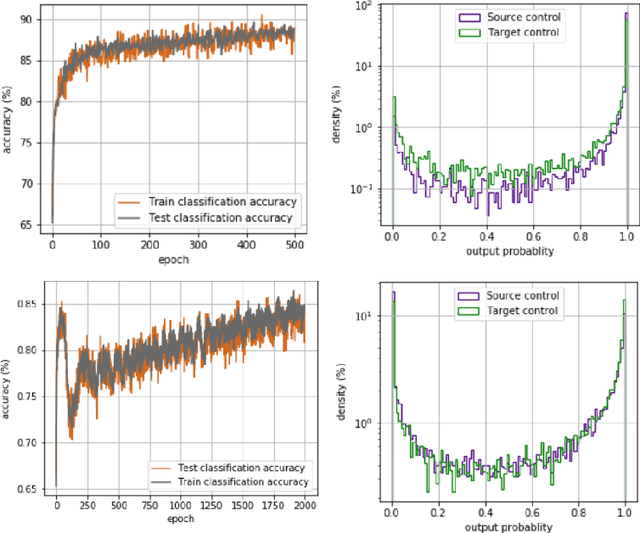
Particle physics or High Energy Physics (HEP) studies the elementary constituents of matter and their interactions with each other. Machine Learning (ML) has played an important role in HEP analysis and has proven extremely successful in this area. Usually, the ML algorithms are trained on numerical simulations of the experimental setup and then applied to the real experimental data. However, any discrepancy between the simulation and real data may lead to dramatic consequences concerning the performances of the algorithm on real data. In this paper, we present an application of domain adaptation using a Domain Adversarial Neural Network trained on public HEP data. We demonstrate the success of this approach to achieve sim-to-real transfer and ensure the consistency of the ML algorithms performances on real and simulated HEP datasets.
Embedded Constrained Feature Construction for High-Energy Physics Data Classification
Dec 17, 2019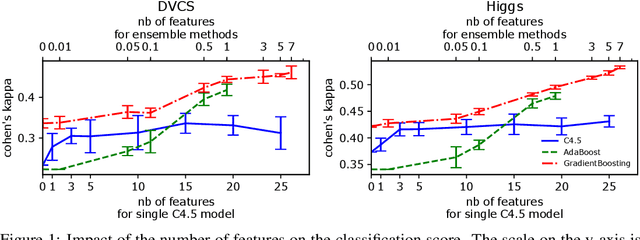
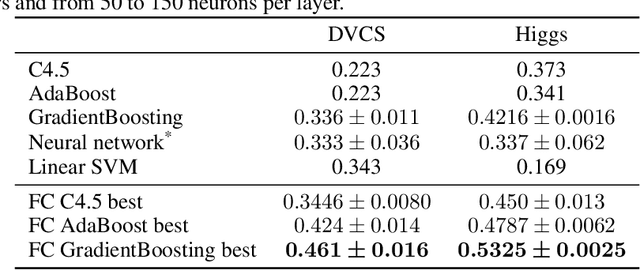
Before any publication, data analysis of high-energy physics experiments must be validated. This validation is granted only if a perfect understanding of the data and the analysis process is demonstrated. Therefore, physicists prefer using transparent machine learning algorithms whose performances highly rely on the suitability of the provided input features. To transform the feature space, feature construction aims at automatically generating new relevant features. Whereas most of previous works in this area perform the feature construction prior to the model training, we propose here a general framework to embed a feature construction technique adapted to the constraints of high-energy physics in the induction of tree-based models. Experiments on two high-energy physics datasets confirm that a significant gain is obtained on the classification scores, while limiting the number of built features. Since the features are built to be interpretable, the whole model is transparent and readable.
Consistent Feature Construction with Constrained Genetic Programming for Experimental Physics
Aug 17, 2019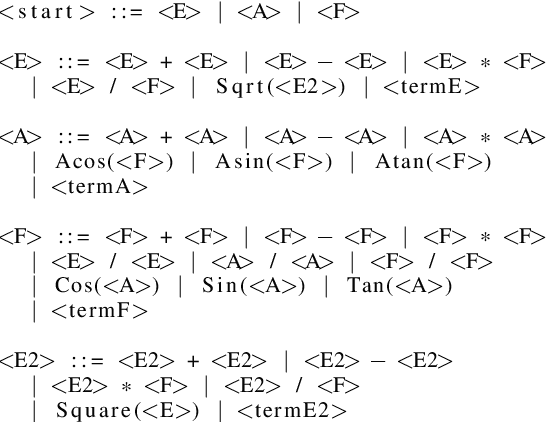
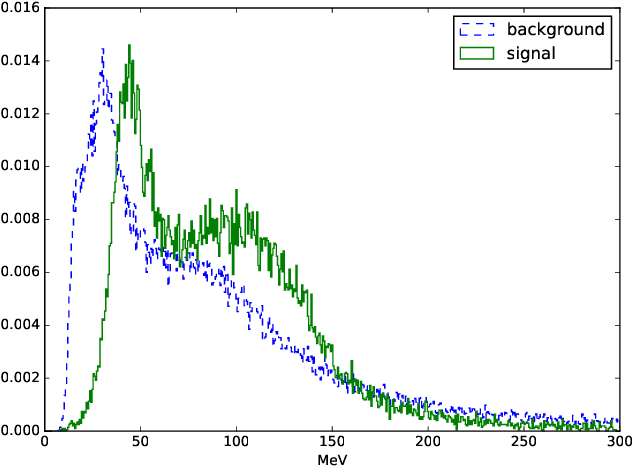
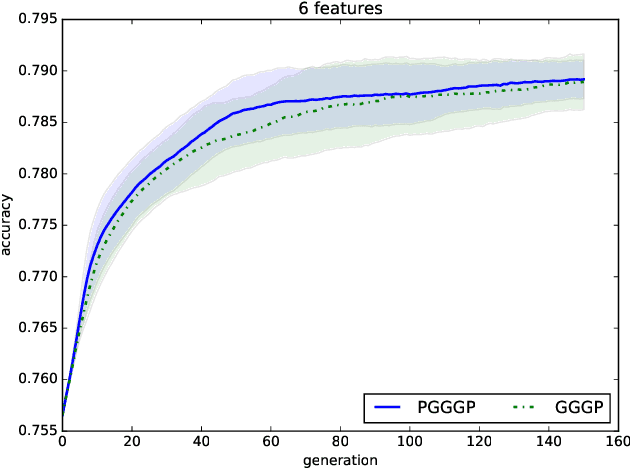
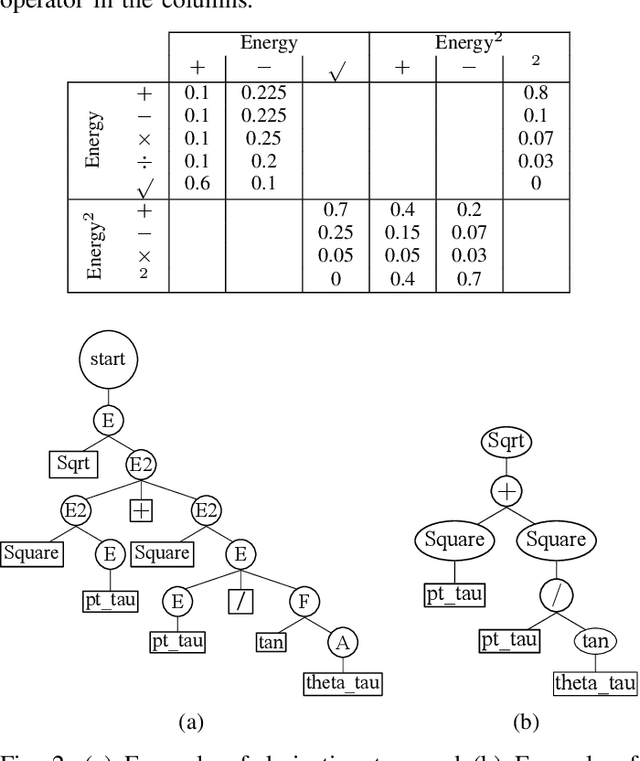
A good feature representation is a determinant factor to achieve high performance for many machine learning algorithms in terms of classification. This is especially true for techniques that do not build complex internal representations of data (e.g. decision trees, in contrast to deep neural networks). To transform the feature space, feature construction techniques build new high-level features from the original ones. Among these techniques, Genetic Programming is a good candidate to provide interpretable features required for data analysis in high energy physics. Classically, original features or higher-level features based on physics first principles are used as inputs for training. However, physicists would benefit from an automatic and interpretable feature construction for the classification of particle collision events. Our main contribution consists in combining different aspects of Genetic Programming and applying them to feature construction for experimental physics. In particular, to be applicable to physics, dimensional consistency is enforced using grammars. Results of experiments on three physics datasets show that the constructed features can bring a significant gain to the classification accuracy. To the best of our knowledge, it is the first time a method is proposed for interpretable feature construction with units of measurement, and that experts in high-energy physics validate the overall approach as well as the interpretability of the built features.
* Accepted in this version to CEC 2019