 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Mechanistic Interpretability to Craft Adversarial Attacks against Large Language Models
Mar 08, 2025
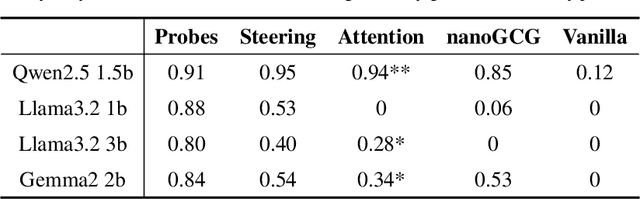


Traditional white-box methods for creating adversarial perturbations against LLMs typically rely only on gradient computation from the targeted model, ignoring the internal mechanisms responsible for attack success or failure. Conversely, interpretability studies that analyze these internal mechanisms lack practical applications beyond runtime interventions. We bridge this gap by introducing a novel white-box approach that leverages mechanistic interpretability techniques to craft practical adversarial inputs. Specifically, we first identify acceptance subspaces - sets of feature vectors that do not trigger the model's refusal mechanisms - then use gradient-based optimization to reroute embeddings from refusal subspaces to acceptance subspaces, effectively achieving jailbreaks. This targeted approach significantly reduces computation cost, achieving attack success rates of 80-95\% on state-of-the-art models including Gemma2, Llama3.2, and Qwen2.5 within minutes or even seconds, compared to existing techniques that often fail or require hours of computation. We believe this approach opens a new direction for both attack research and defense development. Furthermore, it showcases a practical application of mechanistic interpretability where other methods are less efficient, which highlights its utility. The code and generated datasets are available at https://github.com/Sckathach/subspace-rerouting.
DiffGuard: Text-Based Safety Checker for Diffusion Models
Nov 25, 2024Recent advances in Diffusion Models have enabled the generation of images from text, with powerful closed-source models like DALL-E and Midjourney leading the way. However, open-source alternatives, such as StabilityAI's Stable Diffusion, offer comparable capabilities. These open-source models, hosted on Hugging Face, come equipped with ethical filter protections designed to prevent the generation of explicit images. This paper reveals first their limitations and then presents a novel text-based safety filter that outperforms existing solutions. Our research is driven by the critical need to address the misuse of AI-generated content, especially in the context of information warfare. DiffGuard enhances filtering efficacy, achieving a performance that surpasses the best existing filters by over 14%.
Clipping free attacks against artificial neural networks
Mar 28, 2018

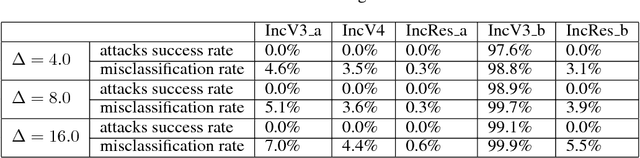

During the last years, a remarkable breakthrough has been made in AI domain thanks to artificial deep neural networks that achieved a great success in many machine learning tasks in computer vision, natural language processing, speech recognition, malware detection and so on. However, they are highly vulnerable to easily crafted adversarial examples. Many investigations have pointed out this fact and different approaches have been proposed to generate attacks while adding a limited perturbation to the original data. The most robust known method so far is the so called C&W attack [1]. Nonetheless, a countermeasure known as feature squeezing coupled with ensemble defense showed that most of these attacks can be destroyed [6]. In this paper, we present a new method we call Centered Initial Attack (CIA) whose advantage is twofold : first, it insures by construction the maximum perturbation to be smaller than a threshold fixed beforehand, without the clipping process that degrades the quality of attacks. Second, it is robust against recently introduced defenses such as feature squeezing, JPEG encoding and even against a voting ensemble of defenses. While its application is not limited to images, we illustrate this using five of the current best classifiers on ImageNet dataset among which two are adversarialy retrained on purpose to be robust against attacks. With a fixed maximum perturbation of only 1.5% on any pixel, around 80% of attacks (targeted) fool the voting ensemble defense and nearly 100% when the perturbation is only 6%. While this shows how it is difficult to defend against CIA attacks, the last section of the paper gives some guidelines to limit their impact.