 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClipping free attacks against artificial neural networks
Paper and Code
Mar 28, 2018

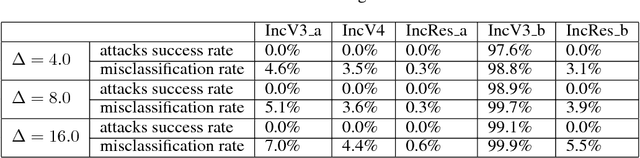

During the last years, a remarkable breakthrough has been made in AI domain thanks to artificial deep neural networks that achieved a great success in many machine learning tasks in computer vision, natural language processing, speech recognition, malware detection and so on. However, they are highly vulnerable to easily crafted adversarial examples. Many investigations have pointed out this fact and different approaches have been proposed to generate attacks while adding a limited perturbation to the original data. The most robust known method so far is the so called C&W attack [1]. Nonetheless, a countermeasure known as feature squeezing coupled with ensemble defense showed that most of these attacks can be destroyed [6]. In this paper, we present a new method we call Centered Initial Attack (CIA) whose advantage is twofold : first, it insures by construction the maximum perturbation to be smaller than a threshold fixed beforehand, without the clipping process that degrades the quality of attacks. Second, it is robust against recently introduced defenses such as feature squeezing, JPEG encoding and even against a voting ensemble of defenses. While its application is not limited to images, we illustrate this using five of the current best classifiers on ImageNet dataset among which two are adversarialy retrained on purpose to be robust against attacks. With a fixed maximum perturbation of only 1.5% on any pixel, around 80% of attacks (targeted) fool the voting ensemble defense and nearly 100% when the perturbation is only 6%. While this shows how it is difficult to defend against CIA attacks, the last section of the paper gives some guidelines to limit their impact.