 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedded Constrained Feature Construction for High-Energy Physics Data Classification
Paper and Code
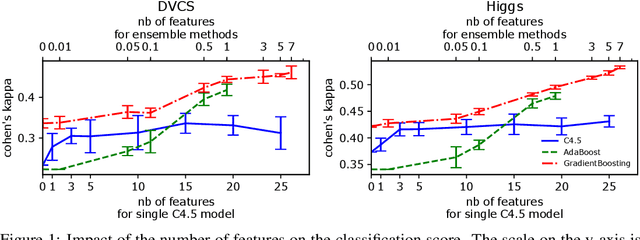
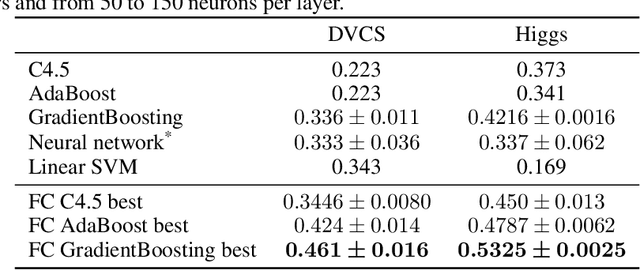
Before any publication, data analysis of high-energy physics experiments must be validated. This validation is granted only if a perfect understanding of the data and the analysis process is demonstrated. Therefore, physicists prefer using transparent machine learning algorithms whose performances highly rely on the suitability of the provided input features. To transform the feature space, feature construction aims at automatically generating new relevant features. Whereas most of previous works in this area perform the feature construction prior to the model training, we propose here a general framework to embed a feature construction technique adapted to the constraints of high-energy physics in the induction of tree-based models. Experiments on two high-energy physics datasets confirm that a significant gain is obtained on the classification scores, while limiting the number of built features. Since the features are built to be interpretable, the whole model is transparent and readable.