 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimation of instrument and noise parameters for inverse problem based on prior diffusion model
Feb 12, 2026This article addresses the issue of estimating observation parameters (response and error parameters) in inverse problems. The focus is on cases where regularization is introduced in a Bayesian framework and the prior is modeled by a diffusion process. In this context, the issue of posterior sampling is well known to be thorny, and a recent paper proposes a notably simple and effective solution. Consequently, it offers an remarkable additional flexibility when it comes to estimating observation parameters. The proposed strategy enables us to define an optimal estimator for both the observation parameters and the image of interest. Furthermore, the strategy provides a means of quantifying uncertainty. In addition, MCMC algorithms allow for the efficient computation of estimates and properties of posteriors, while offering some guarantees. The paper presents several numerical experiments that clearly confirm the computational efficiency and the quality of both estimates and uncertainties quantification.
A Gibbs posterior sampler for inverse problem based on prior diffusion model
Feb 11, 2026This paper addresses the issue of inversion in cases where (1) the observation system is modeled by a linear transformation and additive noise, (2) the problem is ill-posed and regularization is introduced in a Bayesian framework by an a prior density, and (3) the latter is modeled by a diffusion process adjusted on an available large set of examples. In this context, it is known that the issue of posterior sampling is a thorny one. This paper introduces a Gibbs algorithm. It appears that this avenue has not been explored, and we show that this approach is particularly effective and remarkably simple. In addition, it offers a guarantee of convergence in a clearly identified situation. The results are clearly confirmed by numerical simulations.
A Statistical Framework to Investigate the Optimality of Neural Networks for Inverse Problems
Mar 18, 2022
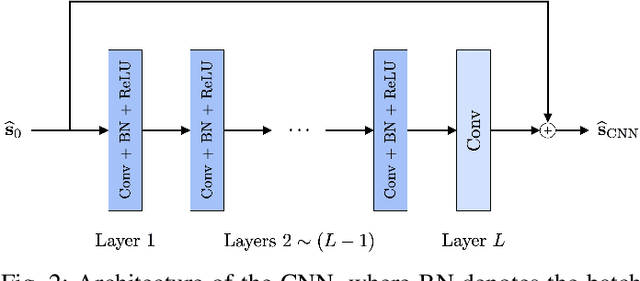
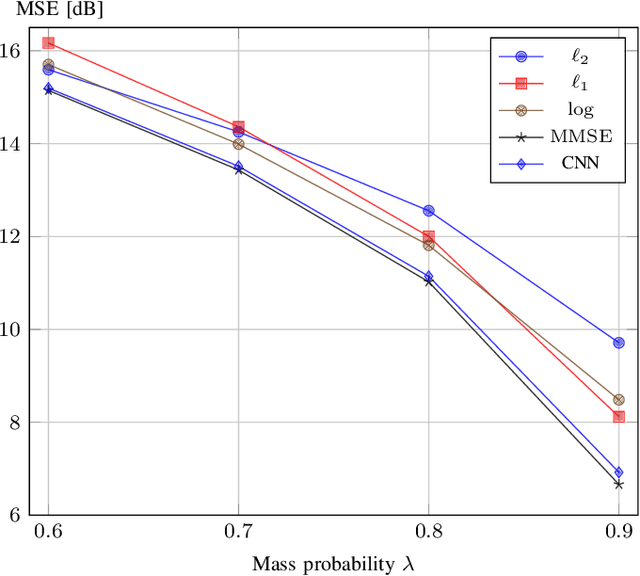
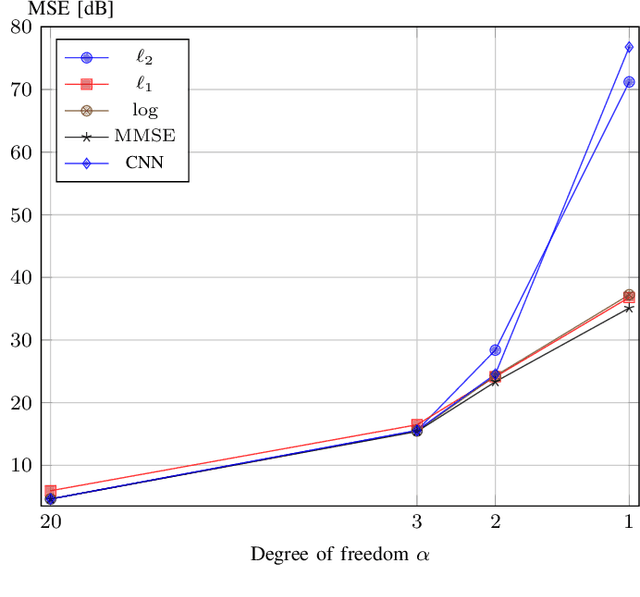
We present a statistical framework to benchmark the performance of neural-network-based reconstruction algorithms for linear inverse problems. The underlying signals in our framework are realizations of sparse stochastic processes and are ideally matched to variational sparsity-promoting techniques, some of which can be reinterpreted as their maximum a posteriori (MAP) estimators. We derive Gibbs sampling schemes to compute the minimum mean square error (MMSE) estimators for processes with Laplace, Student's t and Bernoulli-Laplace innovations. These allow our framework to provide quantitative measures of the degree of optimality (in the mean-square-error sense) for any given reconstruction method. We showcase the use of our framework by benchmarking the performance of CNN architectures for deconvolution and Fourier sampling problems. Our experimental results suggest that while these architectures achieve near-optimal results in many settings, their performance deteriorates severely for signals associated with heavy-tailed distributions.