 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Information Selection for Hypothesis Testing with Misclassification Penalties
Feb 21, 2025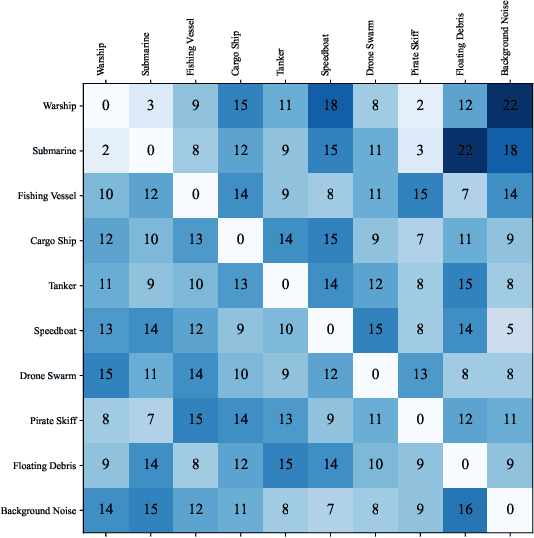
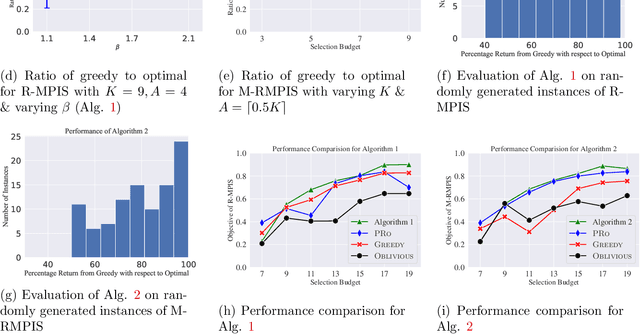
We study the problem of robust information selection for a Bayesian hypothesis testing / classification task, where the goal is to identify the true state of the world from a finite set of hypotheses based on observations from the selected information sources. We introduce a novel misclassification penalty framework, which enables non-uniform treatment of different misclassification events. Extending the classical subset selection framework, we study the problem of selecting a subset of sources that minimize the maximum penalty of misclassification under a limited budget, despite deletions or failures of a subset of the selected sources. We characterize the curvature properties of the objective function and propose an efficient greedy algorithm with performance guarantees. Next, we highlight certain limitations of optimizing for the maximum penalty metric and propose a submodular surrogate metric to guide the selection of the information set. We propose a greedy algorithm with near-optimality guarantees for optimizing the surrogate metric. Finally, we empirically demonstrate the performance of our proposed algorithms in several instances of the information set selection problem.
Submodular Information Selection for Hypothesis Testing with Misclassification Penalties
May 17, 2024

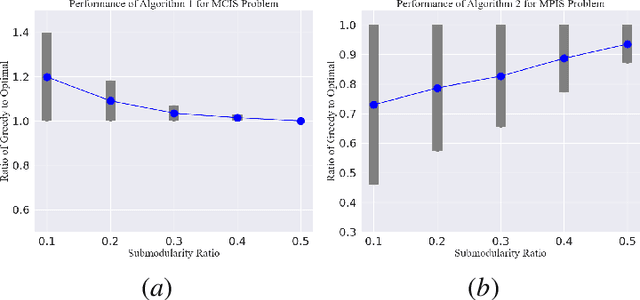

We consider the problem of selecting an optimal subset of information sources for a hypothesis testing/classification task where the goal is to identify the true state of the world from a finite set of hypotheses, based on finite observation samples from the sources. In order to characterize the learning performance, we propose a misclassification penalty framework, which enables non-uniform treatment of different misclassification errors. In a centralized Bayesian learning setting, we study two variants of the subset selection problem: (i) selecting a minimum cost information set to ensure that the maximum penalty of misclassifying the true hypothesis remains bounded and (ii) selecting an optimal information set under a limited budget to minimize the maximum penalty of misclassifying the true hypothesis. Under mild assumptions, we prove that the objective (or constraints) of these combinatorial optimization problems are weak (or approximate) submodular, and establish high-probability performance guarantees for greedy algorithms. Further, we propose an alternate metric for information set selection which is based on the total penalty of misclassification. We prove that this metric is submodular and establish near-optimal guarantees for the greedy algorithms for both the information set selection problems. Finally, we present numerical simulations to validate our theoretical results over several randomly generated instances.
Track based Offline Policy Learning for Overtaking Maneuvers with Autonomous Racecars
Jul 20, 2021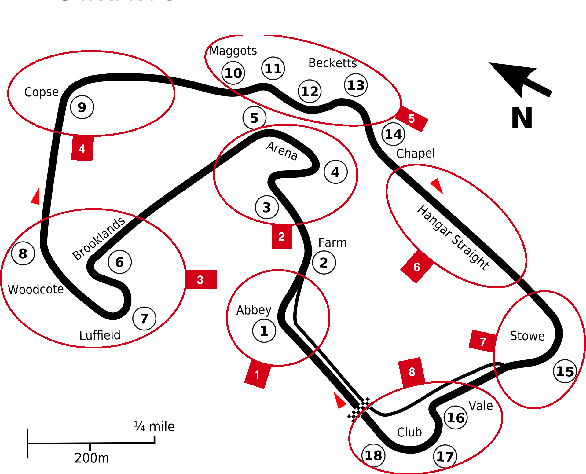
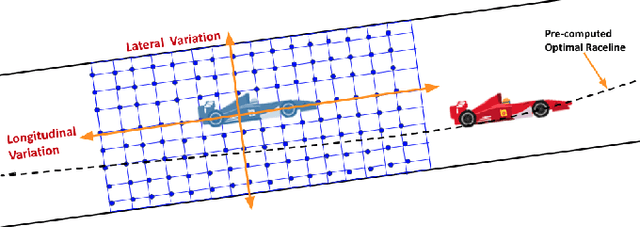

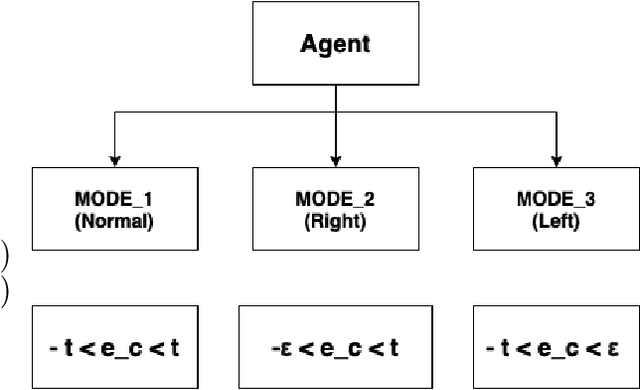
The rising popularity of driver-less cars has led to the research and development in the field of autonomous racing, and overtaking in autonomous racing is a challenging task. Vehicles have to detect and operate at the limits of dynamic handling and decisions in the car have to be made at high speeds and high acceleration. One of the most crucial parts in autonomous racing is path planning and decision making for an overtaking maneuver with a dynamic opponent vehicle. In this paper we present the evaluation of a track based offline policy learning approach for autonomous racing. We define specific track portions and conduct offline experiments to evaluate the probability of an overtaking maneuver based on speed and position of the ego vehicle. Based on these experiments we can define overtaking probability distributions for each of the track portions. Further, we propose a switching MPCC controller setup for incorporating the learnt policies to achieve a higher rate of overtaking maneuvers. By exhaustive simulations, we show that our proposed algorithm is able to increase the number of overtakes at different track portions.