 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePUMA: margin-based data pruning
May 10, 2024Deep learning has been able to outperform humans in terms of classification accuracy in many tasks. However, to achieve robustness to adversarial perturbations, the best methodologies require to perform adversarial training on a much larger training set that has been typically augmented using generative models (e.g., diffusion models). Our main objective in this work, is to reduce these data requirements while achieving the same or better accuracy-robustness trade-offs. We focus on data pruning, where some training samples are removed based on the distance to the model classification boundary (i.e., margin). We find that the existing approaches that prune samples with low margin fails to increase robustness when we add a lot of synthetic data, and explain this situation with a perceptron learning task. Moreover, we find that pruning high margin samples for better accuracy increases the harmful impact of mislabeled perturbed data in adversarial training, hurting both robustness and accuracy. We thus propose PUMA, a new data pruning strategy that computes the margin using DeepFool, and prunes the training samples of highest margin without hurting performance by jointly adjusting the training attack norm on the samples of lowest margin. We show that PUMA can be used on top of the current state-of-the-art methodology in robustness, and it is able to significantly improve the model performance unlike the existing data pruning strategies. Not only PUMA achieves similar robustness with less data, but it also significantly increases the model accuracy, improving the performance trade-off.
Adversarial training with informed data selection
Jan 07, 2023With the increasing amount of available data and advances in computing capabilities, deep neural networks (DNNs) have been successfully employed to solve challenging tasks in various areas, including healthcare, climate, and finance. Nevertheless, state-of-the-art DNNs are susceptible to quasi-imperceptible perturbed versions of the original images -- adversarial examples. These perturbations of the network input can lead to disastrous implications in critical areas where wrong decisions can directly affect human lives. Adversarial training is the most efficient solution to defend the network against these malicious attacks. However, adversarial trained networks generally come with lower clean accuracy and higher computational complexity. This work proposes a data selection (DS) strategy to be applied in the mini-batch training. Based on the cross-entropy loss, the most relevant samples in the batch are selected to update the model parameters in the backpropagation. The simulation results show that a good compromise can be obtained regarding robustness and standard accuracy, whereas the computational complexity of the backpropagation pass is reduced.
Maximum Likelihood Distillation for Robust Modulation Classification
Nov 01, 2022



Deep Neural Networks are being extensively used in communication systems and Automatic Modulation Classification (AMC) in particular. However, they are very susceptible to small adversarial perturbations that are carefully crafted to change the network decision. In this work, we build on knowledge distillation ideas and adversarial training in order to build more robust AMC systems. We first outline the importance of the quality of the training data in terms of accuracy and robustness of the model. We then propose to use the Maximum Likelihood function, which could solve the AMC problem in offline settings, to generate better training labels. Those labels teach the model to be uncertain in challenging conditions, which permits to increase the accuracy, as well as the robustness of the model when combined with adversarial training. Interestingly, we observe that this increase in performance transfers to online settings, where the Maximum Likelihood function cannot be used in practice. Overall, this work highlights the potential of learning to be uncertain in difficult scenarios, compared to directly removing label noise.
On the benefits of knowledge distillation for adversarial robustness
Mar 14, 2022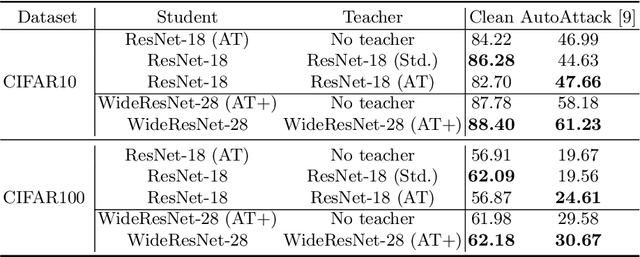
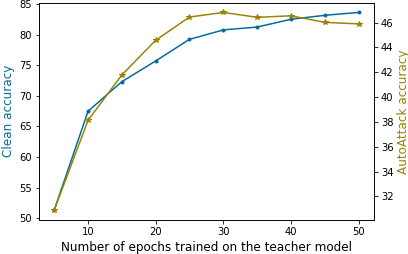
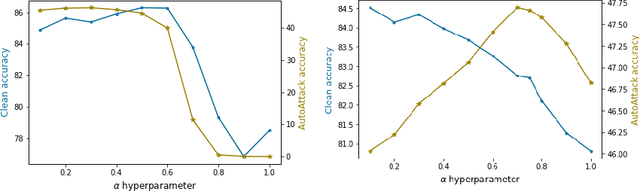
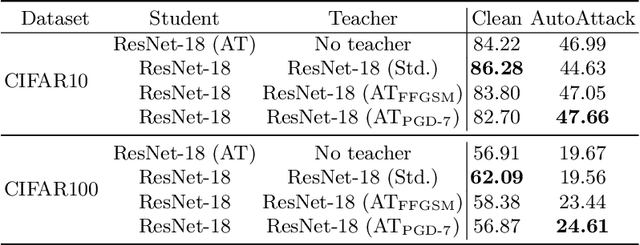
Knowledge distillation is normally used to compress a big network, or teacher, onto a smaller one, the student, by training it to match its outputs. Recently, some works have shown that robustness against adversarial attacks can also be distilled effectively to achieve good rates of robustness on mobile-friendly models. In this work, however, we take a different point of view, and show that knowledge distillation can be used directly to boost the performance of state-of-the-art models in adversarial robustness. In this sense, we present a thorough analysis and provide general guidelines to distill knowledge from a robust teacher and boost the clean and adversarial performance of a student model even further. To that end, we present Adversarial Knowledge Distillation (AKD), a new framework to improve a model's robust performance, consisting on adversarially training a student on a mixture of the original labels and the teacher outputs. Through carefully controlled ablation studies, we show that using early-stopping, model ensembles and weak adversarial training are key techniques to maximize performance of the student, and show that these insights generalize across different robust distillation techniques. Finally, we provide insights on the effect of robust knowledge distillation on the dynamics of the student network, and show that AKD mostly improves the calibration of the network and modify its training dynamics on samples that the model finds difficult to learn, or even memorize.
SafeAMC: Adversarial training for robust modulation recognition models
May 28, 2021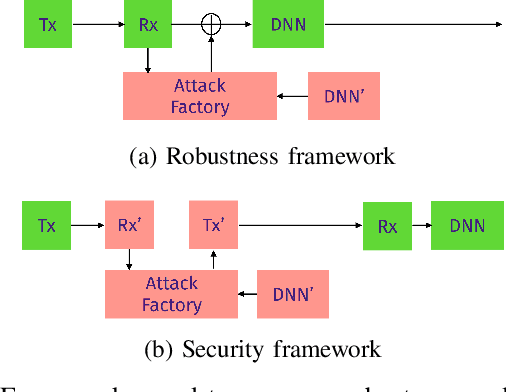
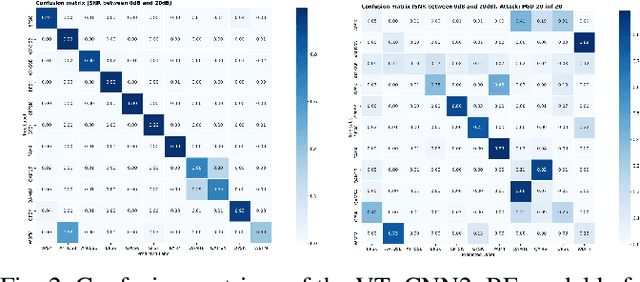
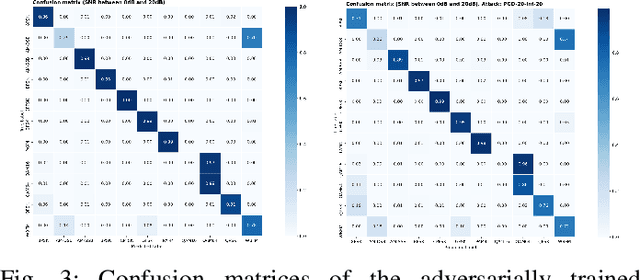

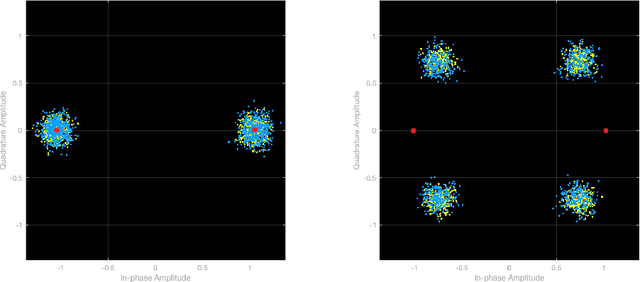
In communication systems, there are many tasks, like modulation recognition, which rely on Deep Neural Networks (DNNs) models. However, these models have been shown to be susceptible to adversarial perturbations, namely imperceptible additive noise crafted to induce misclassification. This raises questions about the security but also the general trust in model predictions. We propose to use adversarial training, which consists of fine-tuning the model with adversarial perturbations, to increase the robustness of automatic modulation recognition (AMC) models. We show that current state-of-the-art models benefit from adversarial training, which mitigates the robustness issues for some families of modulations. We use adversarial perturbations to visualize the features learned, and we found that in robust models the signal symbols are shifted towards the nearest classes in constellation space, like maximum likelihood methods. This confirms that robust models not only are more secure, but also more interpretable, building their decisions on signal statistics that are relevant to modulation recognition.
On the benefits of robust models in modulation recognition
Mar 27, 2021
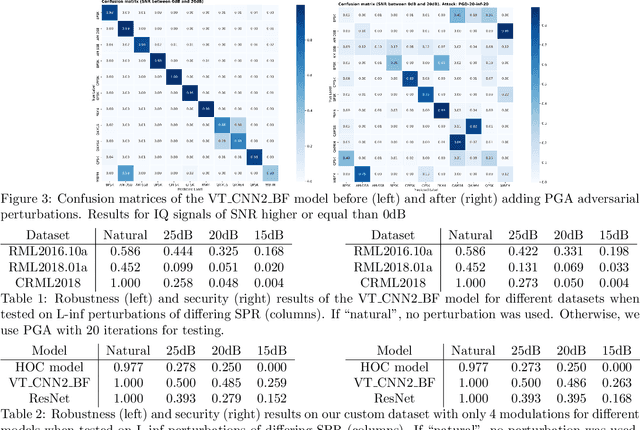
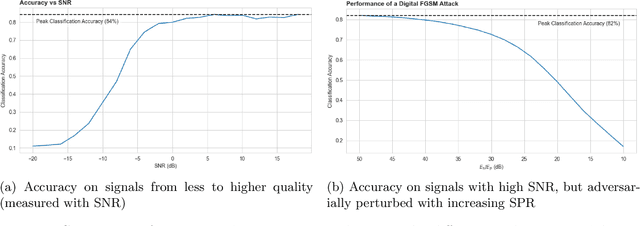
Given the rapid changes in telecommunication systems and their higher dependence on artificial intelligence, it is increasingly important to have models that can perform well under different, possibly adverse, conditions. Deep Neural Networks (DNNs) using convolutional layers are state-of-the-art in many tasks in communications. However, in other domains, like image classification, DNNs have been shown to be vulnerable to adversarial perturbations, which consist of imperceptible crafted noise that when added to the data fools the model into misclassification. This puts into question the security of DNNs in communication tasks, and in particular in modulation recognition. We propose a novel framework to test the robustness of current state-of-the-art models where the adversarial perturbation strength is dependent on the signal strength and measured with the "signal to perturbation ratio" (SPR). We show that current state-of-the-art models are susceptible to these perturbations. In contrast to current research on the topic of image classification, modulation recognition allows us to have easily accessible insights on the usefulness of the features learned by DNNs by looking at the constellation space. When analyzing these vulnerable models we found that adversarial perturbations do not shift the symbols towards the nearest classes in constellation space. This shows that DNNs do not base their decisions on signal statistics that are important for the Bayes-optimal modulation recognition model, but spurious correlations in the training data. Our feature analysis and proposed framework can help in the task of finding better models for communication systems.
Modurec: Recommender Systems with Feature and Time Modulation
Oct 13, 2020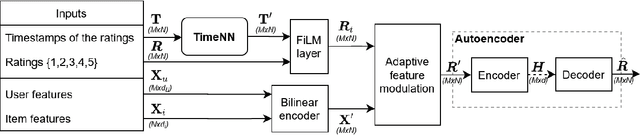
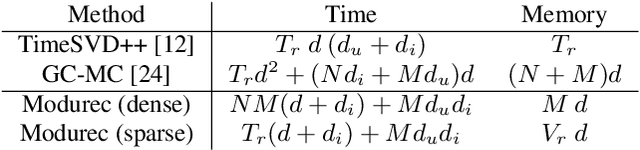

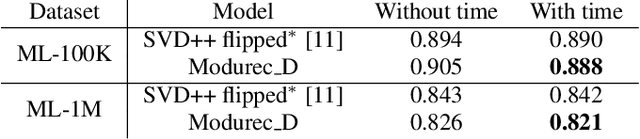
Current state of the art algorithms for recommender systems are mainly based on collaborative filtering, which exploits user ratings to discover latent factors in the data. These algorithms unfortunately do not make effective use of other features, which can help solve two well identified problems of collaborative filtering: cold start (not enough data is available for new users or products) and concept shift (the distribution of ratings changes over time). To address these problems, we propose Modurec: an autoencoder-based method that combines all available information using the feature-wise modulation mechanism, which has demonstrated its effectiveness in several fields. While time information helps mitigate the effects of concept shift, the combination of user and item features improve prediction performance when little data is available. We show on Movielens datasets that these modifications produce state-of-the-art results in most evaluated settings compared with standard autoencoder-based methods and other collaborative filtering approaches.