 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative 2D Reconfiguration using Spatio-Temporal Planning and Load Transferring
Nov 16, 2022



We present progress on the problem of reconfiguring a 2D arrangement of building material by a cooperative set of robots. These robots are subjected to the constraints of avoiding obstacles and maintaining connectivity of the structure. We develop two reconfiguration methods, one based on spatio-temporal planning, and one based on target swapping. Both methods achieve coordinated motion of robots by avoiding deadlocks and maintaining all constraints. Both methods also increase efficiency by reducing the amount of waiting times and lowering combined travel costs. The resulting progress is validated by simulations that also scale the number of robots.
Connected Reconfiguration of Polyominoes Amid Obstacles using RRT*
Jul 04, 2022

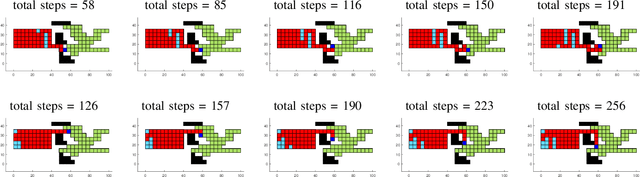
This paper investigates using a sampling-based approach, the RRT*, to reconfiguring a 2D set of connected tiles in complex environments, where multiple obstacles might be present. Since the target application is automated building of discrete, cellular structures using mobile robots, there are constraints that determine what tiles can be picked up and where they can be dropped off during reconfiguration. We compare our approach to two algorithms as global and local planners, and show that we are able to find more efficient build sequences using a reasonable amount of samples, in environments with varying degrees of obstacle space.
Safe Exploration of State and Action Spaces in Reinforcement Learning
Feb 04, 2014



In this paper, we consider the important problem of safe exploration in reinforcement learning. While reinforcement learning is well-suited to domains with complex transition dynamics and high-dimensional state-action spaces, an additional challenge is posed by the need for safe and efficient exploration. Traditional exploration techniques are not particularly useful for solving dangerous tasks, where the trial and error process may lead to the selection of actions whose execution in some states may result in damage to the learning system (or any other system). Consequently, when an agent begins an interaction with a dangerous and high-dimensional state-action space, an important question arises; namely, that of how to avoid (or at least minimize) damage caused by the exploration of the state-action space. We introduce the PI-SRL algorithm which safely improves suboptimal albeit robust behaviors for continuous state and action control tasks and which efficiently learns from the experience gained from the environment. We evaluate the proposed method in four complex tasks: automatic car parking, pole-balancing, helicopter hovering, and business management.