 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexicon-Free Fingerspelling Recognition from Video: Data, Models, and Signer Adaptation
Sep 26, 2016
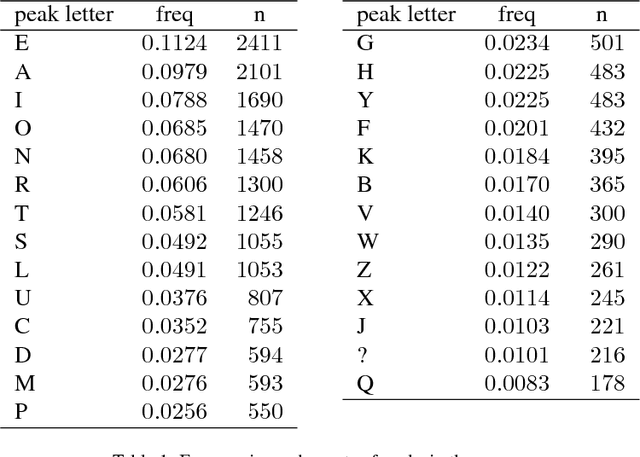
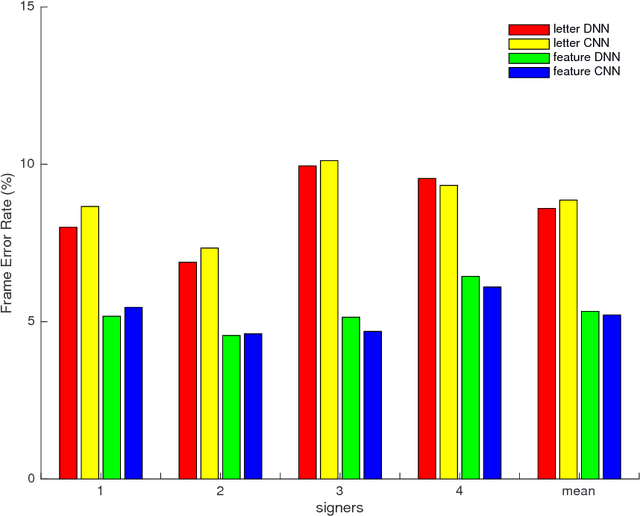
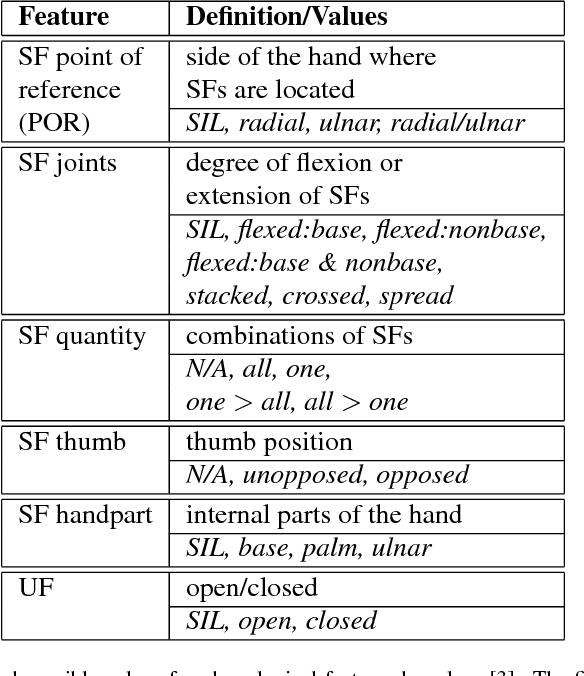
We study the problem of recognizing video sequences of fingerspelled letters in American Sign Language (ASL). Fingerspelling comprises a significant but relatively understudied part of ASL. Recognizing fingerspelling is challenging for a number of reasons: It involves quick, small motions that are often highly coarticulated; it exhibits significant variation between signers; and there has been a dearth of continuous fingerspelling data collected. In this work we collect and annotate a new data set of continuous fingerspelling videos, compare several types of recognizers, and explore the problem of signer variation. Our best-performing models are segmental (semi-Markov) conditional random fields using deep neural network-based features. In the signer-dependent setting, our recognizers achieve up to about 92% letter accuracy. The multi-signer setting is much more challenging, but with neural network adaptation we achieve up to 83% letter accuracies in this setting.