 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEigenvectors of Orthogonally Decomposable Functions
Feb 23, 2018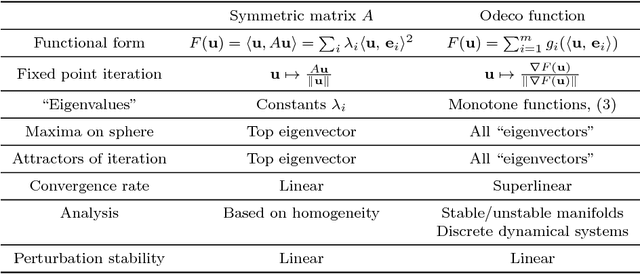
The Eigendecomposition of quadratic forms (symmetric matrices) guaranteed by the spectral theorem is a foundational result in applied mathematics. Motivated by a shared structure found in inferential problems of recent interest---namely orthogonal tensor decompositions, Independent Component Analysis (ICA), topic models, spectral clustering, and Gaussian mixture learning---we generalize the eigendecomposition from quadratic forms to a broad class of "orthogonally decomposable" functions. We identify a key role of convexity in our extension, and we generalize two traditional characterizations of eigenvectors: First, the eigenvectors of a quadratic form arise from the optima structure of the quadratic form on the sphere. Second, the eigenvectors are the fixed points of the power iteration. In our setting, we consider a simple first order generalization of the power method which we call gradient iteration. It leads to efficient and easily implementable methods for basis recovery. It includes influential Machine Learning methods such as cumulant-based FastICA and the tensor power iteration for orthogonally decomposable tensors as special cases. We provide a complete theoretical analysis of gradient iteration using the structure theory of discrete dynamical systems to show almost sure convergence and fast (super-linear) convergence rates. The analysis also extends to the case when the observed function is only approximately orthogonally decomposable, with bounds that are polynomial in dimension and other relevant parameters, such as perturbation size. Our perturbation results can be considered as a non-linear version of the classical Davis-Kahan theorem for perturbations of eigenvectors of symmetric matrices.
The Hidden Convexity of Spectral Clustering
May 04, 2016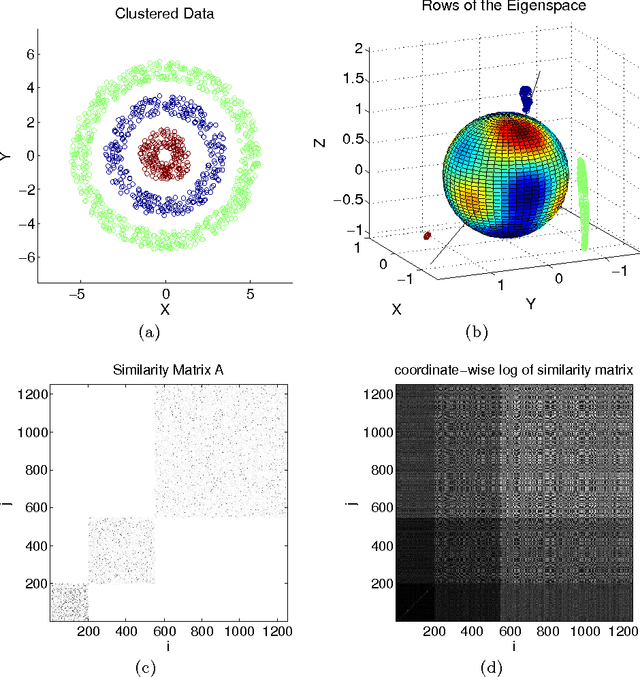

In recent years, spectral clustering has become a standard method for data analysis used in a broad range of applications. In this paper we propose a new class of algorithms for multiway spectral clustering based on optimization of a certain "contrast function" over the unit sphere. These algorithms, partly inspired by certain Independent Component Analysis techniques, are simple, easy to implement and efficient. Geometrically, the proposed algorithms can be interpreted as hidden basis recovery by means of function optimization. We give a complete characterization of the contrast functions admissible for provable basis recovery. We show how these conditions can be interpreted as a "hidden convexity" of our optimization problem on the sphere; interestingly, we use efficient convex maximization rather than the more common convex minimization. We also show encouraging experimental results on real and simulated data.
A Pseudo-Euclidean Iteration for Optimal Recovery in Noisy ICA
Oct 01, 2015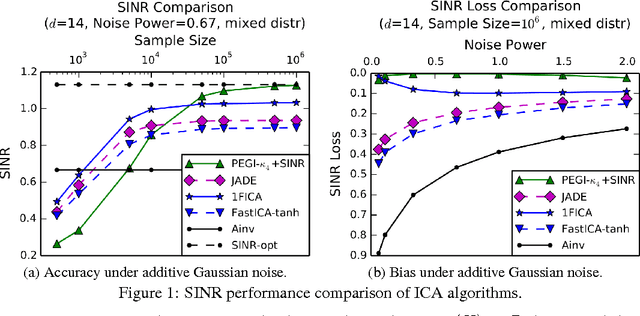
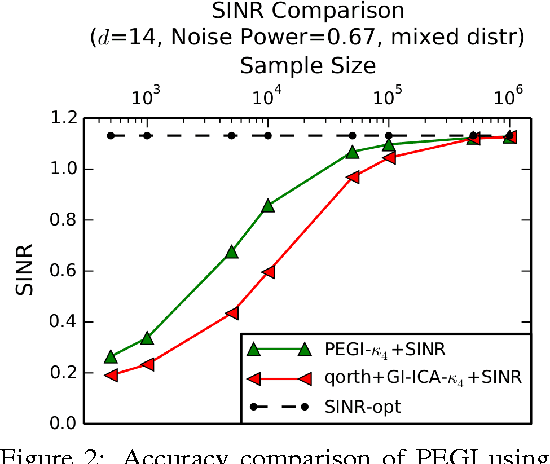
Independent Component Analysis (ICA) is a popular model for blind signal separation. The ICA model assumes that a number of independent source signals are linearly mixed to form the observed signals. We propose a new algorithm, PEGI (for pseudo-Euclidean Gradient Iteration), for provable model recovery for ICA with Gaussian noise. The main technical innovation of the algorithm is to use a fixed point iteration in a pseudo-Euclidean (indefinite "inner product") space. The use of this indefinite "inner product" resolves technical issues common to several existing algorithms for noisy ICA. This leads to an algorithm which is conceptually simple, efficient and accurate in testing. Our second contribution is combining PEGI with the analysis of objectives for optimal recovery in the noisy ICA model. It has been observed that the direct approach of demixing with the inverse of the mixing matrix is suboptimal for signal recovery in terms of the natural Signal to Interference plus Noise Ratio (SINR) criterion. There have been several partial solutions proposed in the ICA literature. It turns out that any solution to the mixing matrix reconstruction problem can be used to construct an SINR-optimal ICA demixing, despite the fact that SINR itself cannot be computed from data. That allows us to obtain a practical and provably SINR-optimal recovery method for ICA with arbitrary Gaussian noise.
The More, the Merrier: the Blessing of Dimensionality for Learning Large Gaussian Mixtures
Feb 18, 2014In this paper we show that very large mixtures of Gaussians are efficiently learnable in high dimension. More precisely, we prove that a mixture with known identical covariance matrices whose number of components is a polynomial of any fixed degree in the dimension n is polynomially learnable as long as a certain non-degeneracy condition on the means is satisfied. It turns out that this condition is generic in the sense of smoothed complexity, as soon as the dimensionality of the space is high enough. Moreover, we prove that no such condition can possibly exist in low dimension and the problem of learning the parameters is generically hard. In contrast, much of the existing work on Gaussian Mixtures relies on low-dimensional projections and thus hits an artificial barrier. Our main result on mixture recovery relies on a new "Poissonization"-based technique, which transforms a mixture of Gaussians to a linear map of a product distribution. The problem of learning this map can be efficiently solved using some recent results on tensor decompositions and Independent Component Analysis (ICA), thus giving an algorithm for recovering the mixture. In addition, we combine our low-dimensional hardness results for Gaussian mixtures with Poissonization to show how to embed difficult instances of low-dimensional Gaussian mixtures into the ICA setting, thus establishing exponential information-theoretic lower bounds for underdetermined ICA in low dimension. To the best of our knowledge, this is the first such result in the literature. In addition to contributing to the problem of Gaussian mixture learning, we believe that this work is among the first steps toward better understanding the rare phenomenon of the "blessing of dimensionality" in the computational aspects of statistical inference.
Blind Signal Separation in the Presence of Gaussian Noise
Jun 09, 2013A prototypical blind signal separation problem is the so-called cocktail party problem, with n people talking simultaneously and n different microphones within a room. The goal is to recover each speech signal from the microphone inputs. Mathematically this can be modeled by assuming that we are given samples from an n-dimensional random variable X=AS, where S is a vector whose coordinates are independent random variables corresponding to each speaker. The objective is to recover the matrix A^{-1} given random samples from X. A range of techniques collectively known as Independent Component Analysis (ICA) have been proposed to address this problem in the signal processing and machine learning literature. Many of these techniques are based on using the kurtosis or other cumulants to recover the components. In this paper we propose a new algorithm for solving the blind signal separation problem in the presence of additive Gaussian noise, when we are given samples from X=AS+\eta, where \eta is drawn from an unknown, not necessarily spherical n-dimensional Gaussian distribution. Our approach is based on a method for decorrelating a sample with additive Gaussian noise under the assumption that the underlying distribution is a linear transformation of a distribution with independent components. Our decorrelation routine is based on the properties of cumulant tensors and can be combined with any standard cumulant-based method for ICA to get an algorithm that is provably robust in the presence of Gaussian noise. We derive polynomial bounds for the sample complexity and error propagation of our method.