 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Mean Embedding Based Hypothesis Tests for Comparing Spatial Point Patterns
May 31, 2019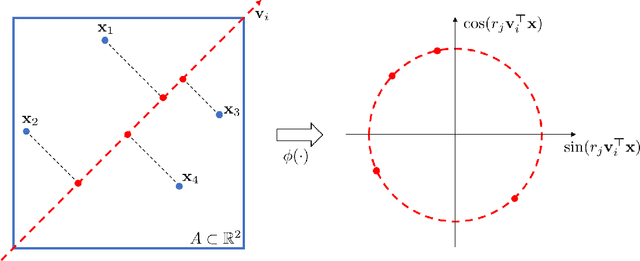


This paper introduces an approach for detecting differences in the first-order structures of spatial point patterns. The proposed approach leverages the kernel mean embedding in a novel way by introducing its approximate version tailored to spatial point processes. While the original embedding is infinite-dimensional and implicit, our approximate embedding is finite-dimensional and comes with explicit closed-form formulas. With its help we reduce the pattern comparison problem to the comparison of means in the Euclidean space. Hypothesis testing is based on conducting $t$-tests on each dimension of the embedding and combining the resulting $p$-values using the harmonic mean $p$-value combination technique. The main advantages of the proposed approach are that it can be applied to both single and replicated pattern comparisons, and that neither bootstrap nor permutation procedures are needed to obtain or calibrate the $p$-values. Our experiments show that the resulting tests are powerful and the $p$-values are well-calibrated; two applications to real world data are presented.
Interpretable Graph-Based Semi-Supervised Learning via Flows
Sep 14, 2017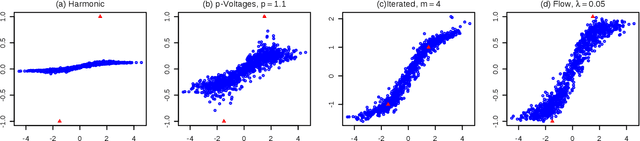
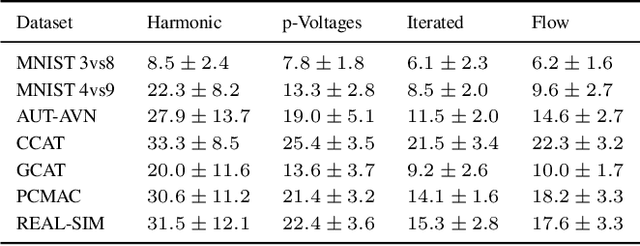

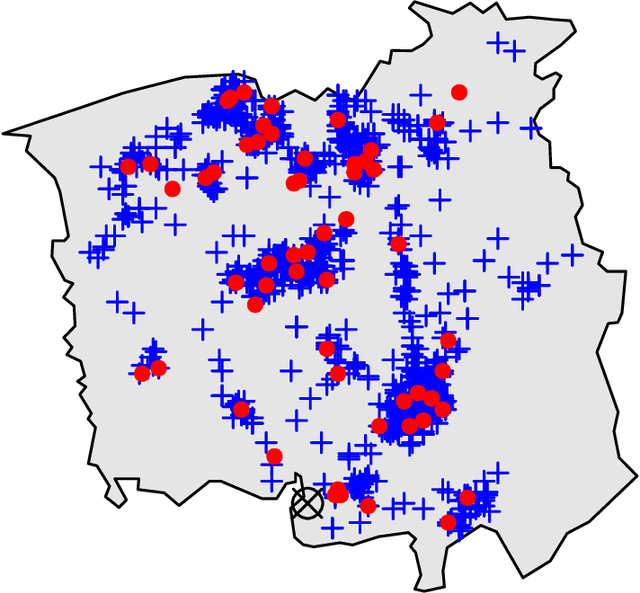
In this paper, we consider the interpretability of the foundational Laplacian-based semi-supervised learning approaches on graphs. We introduce a novel flow-based learning framework that subsumes the foundational approaches and additionally provides a detailed, transparent, and easily understood expression of the learning process in terms of graph flows. As a result, one can visualize and interactively explore the precise subgraph along which the information from labeled nodes flows to an unlabeled node of interest. Surprisingly, the proposed framework avoids trading accuracy for interpretability, but in fact leads to improved prediction accuracy, which is supported both by theoretical considerations and empirical results. The flow-based framework guarantees the maximum principle by construction and can handle directed graphs in an out-of-the-box manner.
Vector Field k-Means: Clustering Trajectories by Fitting Multiple Vector Fields
Aug 31, 2012

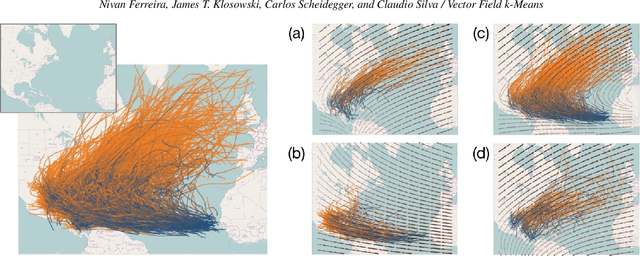
Scientists study trajectory data to understand trends in movement patterns, such as human mobility for traffic analysis and urban planning. There is a pressing need for scalable and efficient techniques for analyzing this data and discovering the underlying patterns. In this paper, we introduce a novel technique which we call vector-field $k$-means. The central idea of our approach is to use vector fields to induce a similarity notion between trajectories. Other clustering algorithms seek a representative trajectory that best describes each cluster, much like $k$-means identifies a representative "center" for each cluster. Vector-field $k$-means, on the other hand, recognizes that in all but the simplest examples, no single trajectory adequately describes a cluster. Our approach is based on the premise that movement trends in trajectory data can be modeled as flows within multiple vector fields, and the vector field itself is what defines each of the clusters. We also show how vector-field $k$-means connects techniques for scalar field design on meshes and $k$-means clustering. We present an algorithm that finds a locally optimal clustering of trajectories into vector fields, and demonstrate how vector-field $k$-means can be used to mine patterns from trajectory data. We present experimental evidence of its effectiveness and efficiency using several datasets, including historical hurricane data, GPS tracks of people and vehicles, and anonymous call records from a large phone company. We compare our results to previous trajectory clustering techniques, and find that our algorithm performs faster in practice than the current state-of-the-art in trajectory clustering, in some examples by a large margin.