 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank Key Value Attention
Jan 16, 2026Transformer pretraining is increasingly constrained by memory and compute requirements, with the key-value (KV) cache emerging as a dominant bottleneck during training and autoregressive decoding. We propose \textit{low-rank KV adaptation} (LRKV), a simple modification of multi-head attention that reduces KV cache memory by exploiting redundancy across attention heads while preserving full token-level resolution. Each layer uses a shared full-rank KV projection augmented with low-rank, head-specific residuals, yielding a continuous trade-off between complete sharing and fully independent attention. LRKV is a drop-in replacement for standard multi-head attention and directly subsumes query-sharing approaches such as multi-query and grouped-query attention, while remaining distinct from latent-compression methods such as multi-latent attention (MLA). Across large-scale pretraining experiments, LRKV consistently achieves faster loss reduction, lower validation perplexity, and stronger downstream task performance than standard attention, MQA/GQA, and MLA. At the 2.5B scale, LRKV outperforms standard attention while using roughly half the KV cache, and reaches equivalent model quality with up to \textbf{20-25\% less training compute} when measured in cumulative FLOPs. To explain these gains, we analyze attention head structure in operator space and show that LRKV preserves nearly all functional head diversity relative to standard attention, whereas more aggressive KV-sharing mechanisms rely on compensatory query specialization. Together, these results establish LRKV as a practical and effective attention mechanism for scaling Transformer pretraining under memory- and compute-constrained regimes.
A Survey on Word Meta-Embedding Learning
Apr 25, 2022Meta-embedding (ME) learning is an emerging approach that attempts to learn more accurate word embeddings given existing (source) word embeddings as the sole input. Due to their ability to incorporate semantics from multiple source embeddings in a compact manner with superior performance, ME learning has gained popularity among practitioners in NLP. To the best of our knowledge, there exist no prior systematic survey on ME learning and this paper attempts to fill this need. We classify ME learning methods according to multiple factors such as whether they (a) operate on static or contextualised embeddings, (b) trained in an unsupervised manner or (c) fine-tuned for a particular task/domain. Moreover, we discuss the limitations of existing ME learning methods and highlight potential future research directions.
* Proceedings of the 31st International Joint Conference on Artificial Intelligence (IJCAI-2022)
I Wish I Would Have Loved This One, But I Didn't -- A Multilingual Dataset for Counterfactual Detection in Product Reviews
Apr 14, 2021



Counterfactual statements describe events that did not or cannot take place. We consider the problem of counterfactual detection (CFD) in product reviews. For this purpose, we annotate a multilingual CFD dataset from Amazon product reviews covering counterfactual statements written in English, German, and Japanese languages. The dataset is unique as it contains counterfactuals in multiple languages, covers a new application area of e-commerce reviews, and provides high quality professional annotations. We train CFD models using different text representation methods and classifiers. We find that these models are robust against the selectional biases introduced due to cue phrase-based sentence selection. Moreover, our CFD dataset is compatible with prior datasets and can be merged to learn accurate CFD models. Applying machine translation on English counterfactual examples to create multilingual data performs poorly, demonstrating the language-specificity of this problem, which has been ignored so far.
Do not let the history haunt you -- Mitigating Compounding Errors in Conversational Question Answering
May 12, 2020
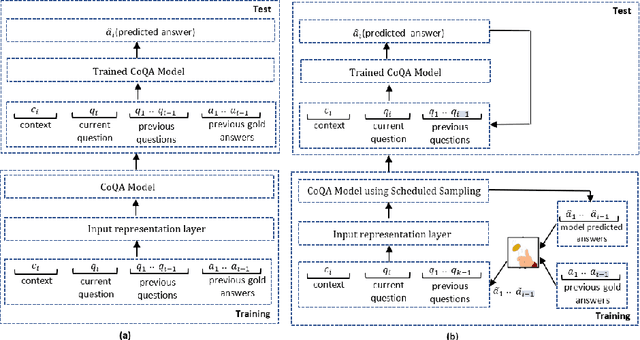

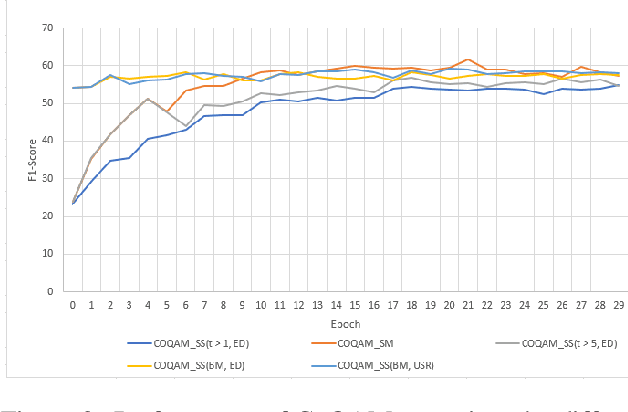
The Conversational Question Answering (CoQA) task involves answering a sequence of inter-related conversational questions about a contextual paragraph. Although existing approaches employ human-written ground-truth answers for answering conversational questions at test time, in a realistic scenario, the CoQA model will not have any access to ground-truth answers for the previous questions, compelling the model to rely upon its own previously predicted answers for answering the subsequent questions. In this paper, we find that compounding errors occur when using previously predicted answers at test time, significantly lowering the performance of CoQA systems. To solve this problem, we propose a sampling strategy that dynamically selects between target answers and model predictions during training, thereby closely simulating the situation at test time. Further, we analyse the severity of this phenomena as a function of the question type, conversation length and domain type.
Automatic Taxonomy Generation - A Use-Case in the Legal Domain
Oct 04, 2017



A key challenge in the legal domain is the adaptation and representation of the legal knowledge expressed through texts, in order for legal practitioners and researchers to access this information easier and faster to help with compliance related issues. One way to approach this goal is in the form of a taxonomy of legal concepts. While this task usually requires a manual construction of terms and their relations by domain experts, this paper describes a methodology to automatically generate a taxonomy of legal noun concepts. We apply and compare two approaches on a corpus consisting of statutory instruments for UK, Wales, Scotland and Northern Ireland laws.