 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Wish I Would Have Loved This One, But I Didn't -- A Multilingual Dataset for Counterfactual Detection in Product Reviews
Apr 14, 2021



Counterfactual statements describe events that did not or cannot take place. We consider the problem of counterfactual detection (CFD) in product reviews. For this purpose, we annotate a multilingual CFD dataset from Amazon product reviews covering counterfactual statements written in English, German, and Japanese languages. The dataset is unique as it contains counterfactuals in multiple languages, covers a new application area of e-commerce reviews, and provides high quality professional annotations. We train CFD models using different text representation methods and classifiers. We find that these models are robust against the selectional biases introduced due to cue phrase-based sentence selection. Moreover, our CFD dataset is compatible with prior datasets and can be merged to learn accurate CFD models. Applying machine translation on English counterfactual examples to create multilingual data performs poorly, demonstrating the language-specificity of this problem, which has been ignored so far.
Language-Independent Tokenisation Rivals Language-Specific Tokenisation for Word Similarity Prediction
Feb 25, 2020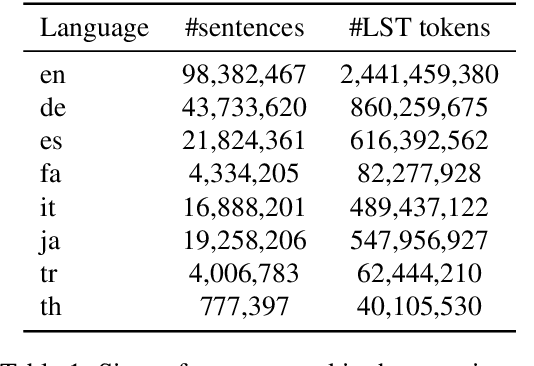

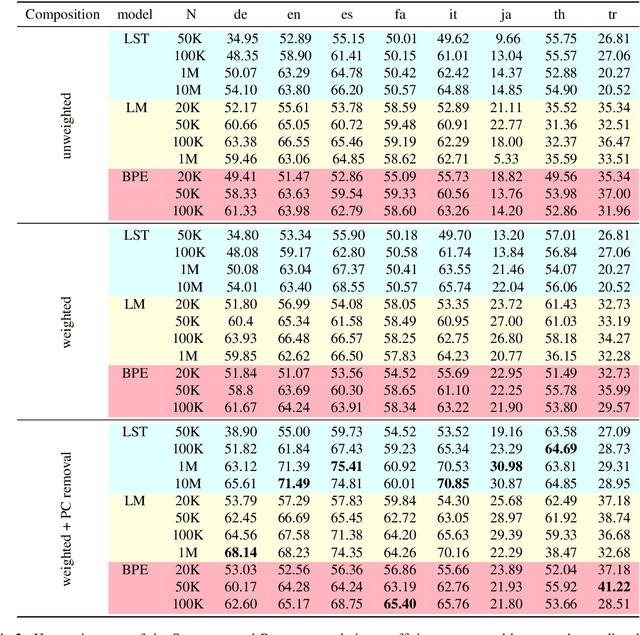

Language-independent tokenisation (LIT) methods that do not require labelled language resources or lexicons have recently gained popularity because of their applicability in resource-poor languages. Moreover, they compactly represent a language using a fixed size vocabulary and can efficiently handle unseen or rare words. On the other hand, language-specific tokenisation (LST) methods have a long and established history, and are developed using carefully created lexicons and training resources. Unlike subtokens produced by LIT methods, LST methods produce valid morphological subwords. Despite the contrasting trade-offs between LIT vs. LST methods, their performance on downstream NLP tasks remain unclear. In this paper, we empirically compare the two approaches using semantic similarity measurement as an evaluation task across a diverse set of languages. Our experimental results covering eight languages show that LST consistently outperforms LIT when the vocabulary size is large, but LIT can produce comparable or better results than LST in many languages with comparatively smaller (i.e. less than 100K words) vocabulary sizes, encouraging the use of LIT when language-specific resources are unavailable, incomplete or a smaller model is required. Moreover, we find that smoothed inverse frequency (SIF) to be an accurate method to create word embeddings from subword embeddings for multilingual semantic similarity prediction tasks. Further analysis of the nearest neighbours of tokens show that semantically and syntactically related tokens are closely embedded in subword embedding spaces
Positive-Unlabeled Learning with Non-Negative Risk Estimator
Nov 04, 2017



From only positive (P) and unlabeled (U) data, a binary classifier could be trained with PU learning, in which the state of the art is unbiased PU learning. However, if its model is very flexible, empirical risks on training data will go negative, and we will suffer from serious overfitting. In this paper, we propose a non-negative risk estimator for PU learning: when getting minimized, it is more robust against overfitting, and thus we are able to use very flexible models (such as deep neural networks) given limited P data. Moreover, we analyze the bias, consistency, and mean-squared-error reduction of the proposed risk estimator, and bound the estimation error of the resulting empirical risk minimizer. Experiments demonstrate that our risk estimator fixes the overfitting problem of its unbiased counterparts.