 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Prediction Models as General Visual Encoders
May 25, 2024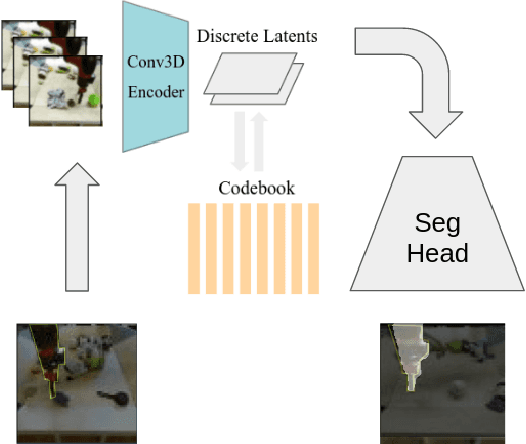


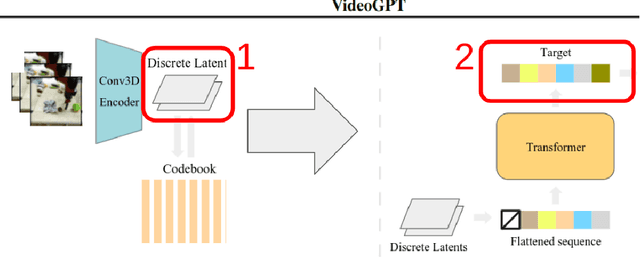
This study explores the potential of open-source video conditional generation models as encoders for downstream tasks, focusing on instance segmentation using the BAIR Robot Pushing Dataset. The researchers propose using video prediction models as general visual encoders, leveraging their ability to capture critical spatial and temporal information which is essential for tasks such as instance segmentation. Inspired by human vision studies, particularly Gestalts principle of common fate, the approach aims to develop a latent space representative of motion from images to effectively discern foreground from background information. The researchers utilize a 3D Vector-Quantized Variational Autoencoder 3D VQVAE video generative encoder model conditioned on an input frame, coupled with downstream segmentation tasks. Experiments involve adapting pre-trained video generative models, analyzing their latent spaces, and training custom decoders for foreground-background segmentation. The findings demonstrate promising results in leveraging generative pretext learning for downstream tasks, working towards enhanced scene analysis and segmentation in computer vision applications.
Modular, Resilient, and Scalable System Design Approaches -- Lessons learned in the years after DARPA Subterranean Challenge
Apr 27, 2024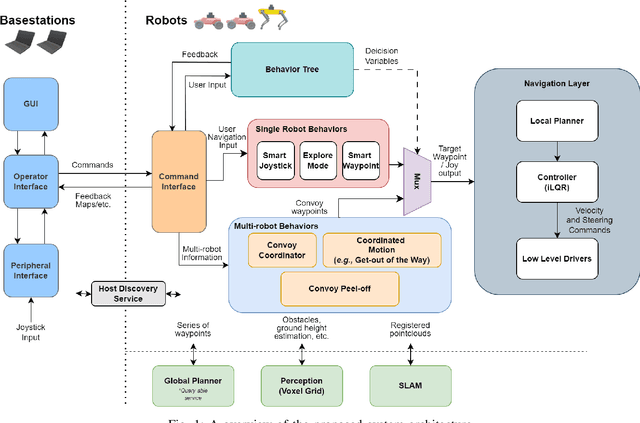
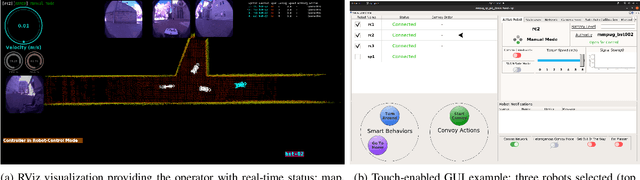
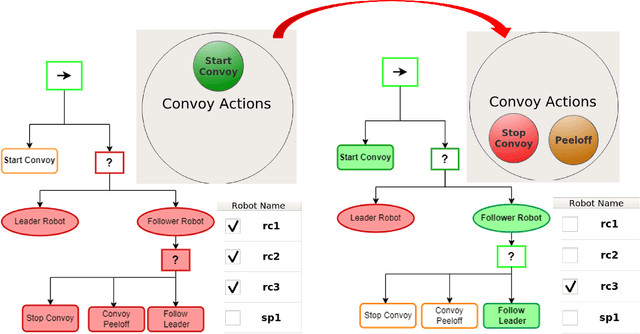
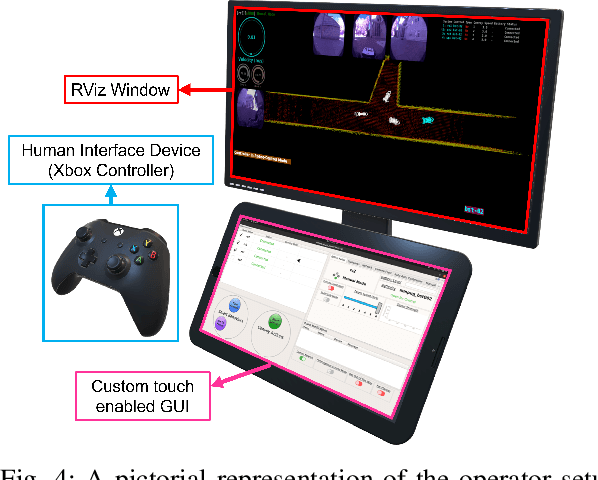
Field robotics applications, such as search and rescue, involve robots operating in large, unknown areas. These environments present unique challenges that compound the difficulties faced by a robot operator. The use of multi-robot teams, assisted by carefully designed autonomy, help reduce operator workload and allow the operator to effectively coordinate robot capabilities. In this work, we present a system architecture designed to optimize both robot autonomy and the operator experience in multi-robot scenarios. Drawing on lessons learned from our team's participation in the DARPA SubT Challenge, our architecture emphasizes modularity and interoperability. We empower the operator by allowing for adjustable levels of autonomy ("sliding mode autonomy"). We enhance the operator experience by using intuitive, adaptive interfaces that suggest context-aware actions to simplify control. Finally, we describe how the proposed architecture enables streamlined development of new capabilities for effective deployment of robot autonomy in the field.
Longitudinal Control Volumes: A Novel Centralized Estimation and Control Framework for Distributed Multi-Agent Sorting Systems
Feb 03, 2024



Centralized control of a multi-agent system improves upon distributed control especially when multiple agents share a common task e.g., sorting different materials in a recycling facility. Traditionally, each agent in a sorting facility is tuned individually which leads to suboptimal performance if one agent is less efficient than the others. Centralized control overcomes this bottleneck by leveraging global system state information, but it can be computationally expensive. In this work, we propose a novel framework called Longitudinal Control Volumes (LCV) to model the flow of material in a recycling facility. We then employ a Kalman Filter that incorporates local measurements of materials into a global estimation of the material flow in the system. We utilize a model predictive control algorithm that optimizes the rate of material flow using the global state estimate in real-time. We show that our proposed framework outperforms distributed control methods by 40-100% in simulation and physical experiments.