 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Extensible Interactive Interface for Agent Design
Jun 10, 2019



In artificial intelligence, we often specify tasks through a reward function. While this works well in some settings, many tasks are hard to specify this way. In deep reinforcement learning, for example, directly specifying a reward as a function of a high-dimensional observation is challenging. Instead, we present an interface for specifying tasks interactively using demonstrations. Our approach defines a set of increasingly complex policies. The interface allows the user to switch between these policies at fixed intervals to generate demonstrations of novel, more complex, tasks. We train new policies based on these demonstrations and repeat the process. We present a case study of our approach in the Lunar Lander domain, and show that this simple approach can quickly learn a successful landing policy and outperforms an existing comparison-based deep RL method.
Decentralized Control of a Hexapod Robot Using a Wireless Time Synchronized Network
Aug 23, 2018
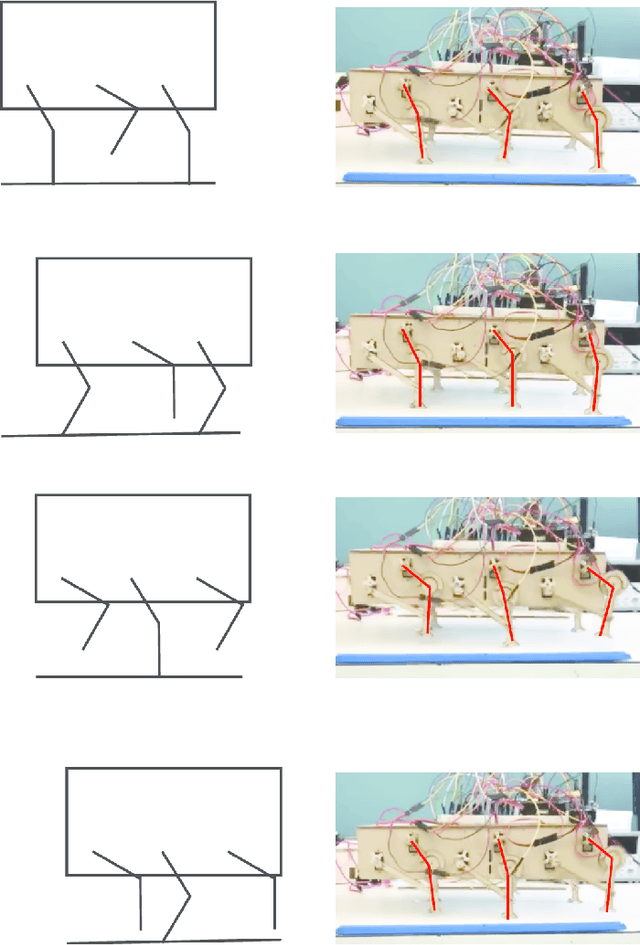

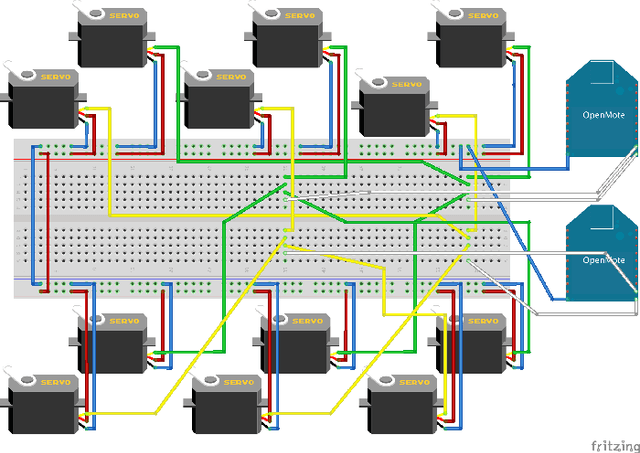
Robots and control systems rely upon precise timing of sensors and actuators in order to operate intelligently. We present a functioning hexapod robot that walks with a dual tripod gait; each tripod is actuated using its own local controller running on a separate wireless node. We compare and report the results of operating the robot using two different decentralized control schemes. With the first scheme, each controller relies on its own local clock to generate control signals for the tripod it controls. With the second scheme, each controller relies on a variable that is local to itself but that is necessarily the same across controllers as a by-product of their host nodes being part of a time synchronized IEEE802.15.4e network. The gait synchronization error (time difference between what both controllers believe is the start of the gait period) grows linearly when the controllers use their local clocks, but remains bounded to within 112 microseconds when the controllers use their nodes' time synchronized local variable.