 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Extensible Interactive Interface for Agent Design
Paper and Code
Jun 10, 2019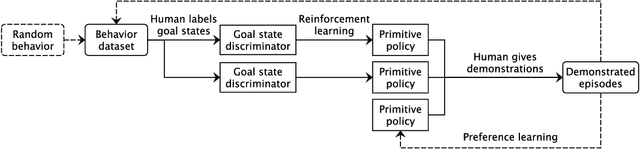



In artificial intelligence, we often specify tasks through a reward function. While this works well in some settings, many tasks are hard to specify this way. In deep reinforcement learning, for example, directly specifying a reward as a function of a high-dimensional observation is challenging. Instead, we present an interface for specifying tasks interactively using demonstrations. Our approach defines a set of increasingly complex policies. The interface allows the user to switch between these policies at fixed intervals to generate demonstrations of novel, more complex, tasks. We train new policies based on these demonstrations and repeat the process. We present a case study of our approach in the Lunar Lander domain, and show that this simple approach can quickly learn a successful landing policy and outperforms an existing comparison-based deep RL method.