 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEC: Machine-Learning-Assisted Generalized Entropy Calibration for Semi-Supervised Mean Estimation
Apr 07, 2026Obtaining high-quality labels is costly, whereas unlabeled covariates are often abundant, motivating semi-supervised inference methods with reliable uncertainty quantification. Prediction-powered inference (PPI) leverages a machine-learning predictor trained on a small labeled sample to improve efficiency, but it can lose efficiency under model misspecification and suffer from coverage distortions due to label reuse. We introduce Machine-Learning-Assisted Generalized Entropy Calibration (MEC), a cross-fitted, calibration-weighted variant of PPI. MEC improves efficiency by reweighting labeled samples to better align with the target population, using a principled calibration framework based on Bregman projections. This yields robustness to affine transformations of the predictor and relaxes requirements for validity by replacing conditions on raw prediction error with weaker projection-error conditions. As a result, MEC attains the semiparametric efficiency bound under weaker assumptions than existing PPI variants. Across simulations and a real-data application, MEC achieves near-nominal coverage and tighter confidence intervals than CF-PPI and vanilla PPI.
Statistical inference using Regularized M-estimation in the reproducing kernel Hilbert space for handling missing data
Jul 15, 2021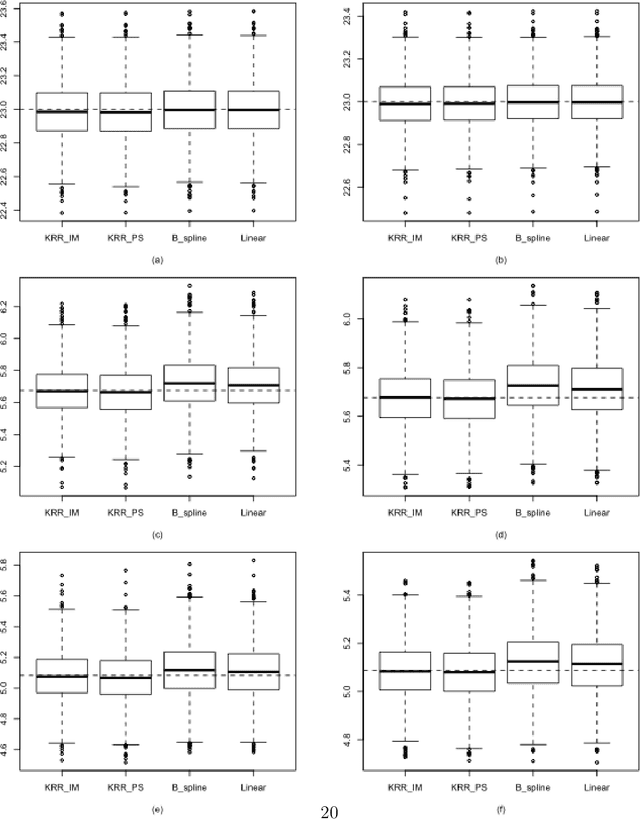
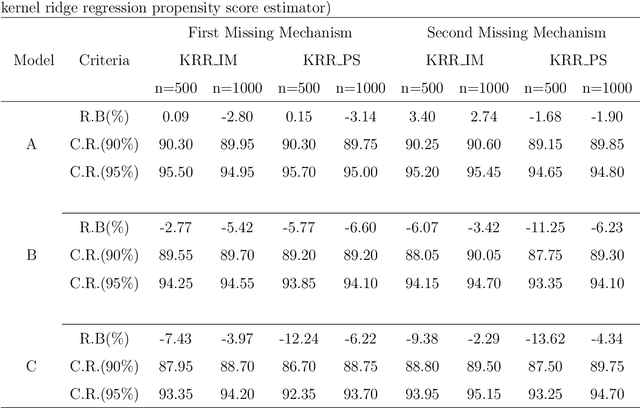
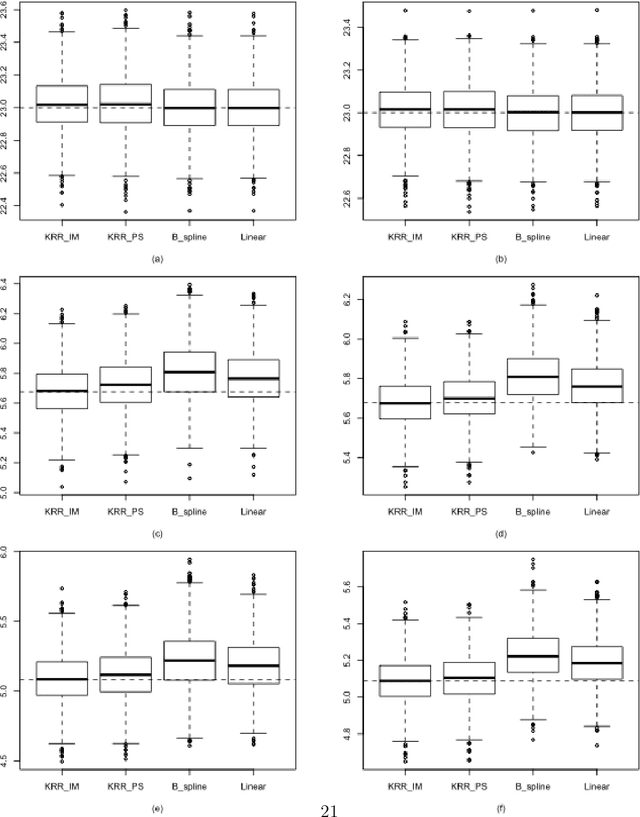
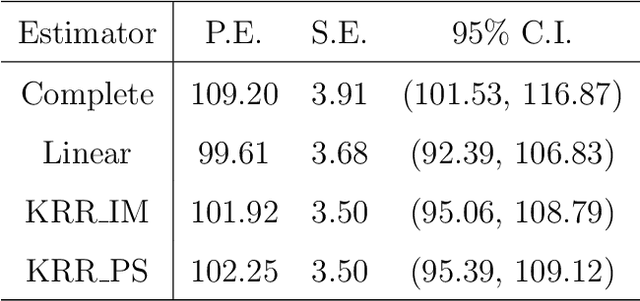
Imputation and propensity score weighting are two popular techniques for handling missing data. We address these problems using the regularized M-estimation techniques in the reproducing kernel Hilbert space. Specifically, we first use the kernel ridge regression to develop imputation for handling item nonresponse. While this nonparametric approach is potentially promising for imputation, its statistical properties are not investigated in the literature. Under some conditions on the order of the tuning parameter, we first establish the root-$n$ consistency of the kernel ridge regression imputation estimator and show that it achieves the lower bound of the semiparametric asymptotic variance. A nonparametric propensity score estimator using the reproducing kernel Hilbert space is also developed by a novel application of the maximum entropy method for the density ratio function estimation. We show that the resulting propensity score estimator is asymptotically equivalent to the kernel ridge regression imputation estimator. Results from a limited simulation study are also presented to confirm our theory. The proposed method is applied to analyze the air pollution data measured in Beijing, China.
Maximum sampled conditional likelihood for informative subsampling
Nov 11, 2020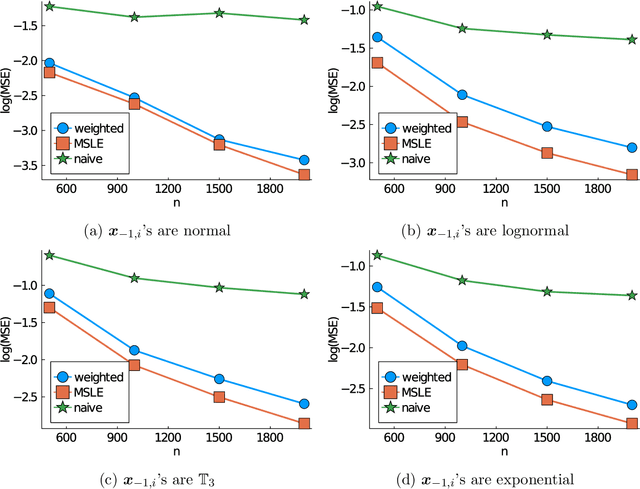
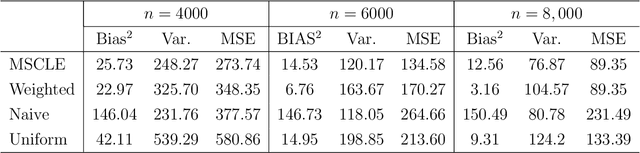
Subsampling is a computationally effective approach to extract information from massive data sets when computing resources are limited. After a subsample is taken from the full data, most available methods use an inverse probability weighted objective function to estimate the model parameters. This type of weighted estimator does not fully utilize information in the selected subsample. In this paper, we propose to use the maximum sampled conditional likelihood estimator (MSCLE) based on the sampled data. We established the asymptotic normality of the MSCLE and prove that its asymptotic variance covariance matrix is the smallest among a class of asymptotically unbiased estimators, including the inverse probability weighted estimator. We further discuss the asymptotic results with the L-optimal subsampling probabilities and illustrate the estimation procedure with generalized linear models. Numerical experiments are provided to evaluate the practical performance of the proposed method.
Imputation estimators for unnormalized models with missing data
Mar 08, 2019


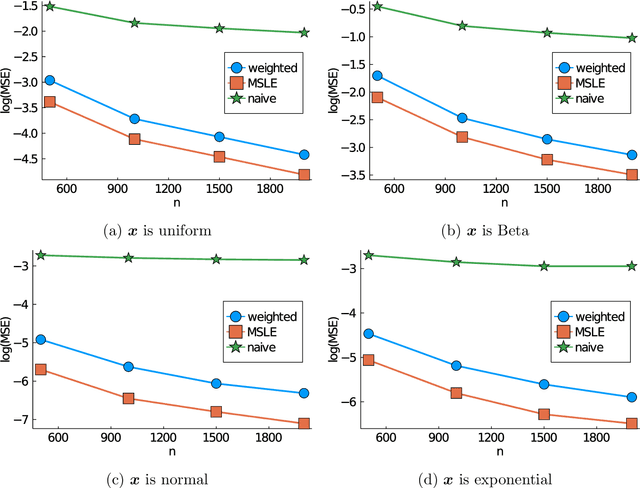
We propose estimation methods for unnormalized models with missing data. The key concept is to combine a modern imputation technique with estimators for unnormalized models including noise contrastive estimation and score matching. Further, we derive asymptotic distributions of the proposed estimators and construct the confidence intervals. The application to truncated Gaussian graphical models with missing data shows the validity of the proposed methods.