 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA hybrid convolutional neural network/active contour approach to segmenting dead trees in aerial imagery
Dec 06, 2021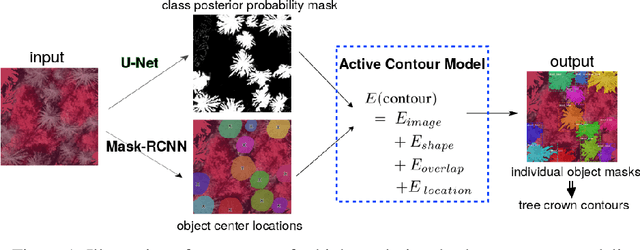
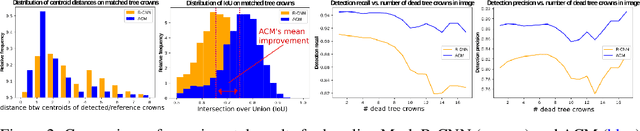


The stability and ability of an ecosystem to withstand climate change is directly linked to its biodiversity. Dead trees are a key indicator of overall forest health, housing one-third of forest ecosystem biodiversity, and constitute 8%of the global carbon stocks. They are decomposed by several natural factors, e.g. climate, insects and fungi. Accurate detection and modeling of dead wood mass is paramount to understanding forest ecology, the carbon cycle and decomposers. We present a novel method to construct precise shape contours of dead trees from aerial photographs by combining established convolutional neural networks with a novel active contour model in an energy minimization framework. Our approach yields superior performance accuracy over state-of-the-art in terms of precision, recall, and intersection over union of detected dead trees. This improved performance is essential to meet emerging challenges caused by climate change (and other man-made perturbations to the systems), particularly to monitor and estimate carbon stock decay rates, monitor forest health and biodiversity, and the overall effects of dead wood on and from climate change.
GP-select: Accelerating EM using adaptive subspace preselection
Jul 17, 2016We propose a nonparametric procedure to achieve fast inference in generative graphical models when the number of latent states is very large. The approach is based on iterative latent variable preselection, where we alternate between learning a 'selection function' to reveal the relevant latent variables, and use this to obtain a compact approximation of the posterior distribution for EM; this can make inference possible where the number of possible latent states is e.g. exponential in the number of latent variables, whereas an exact approach would be computationally unfeasible. We learn the selection function entirely from the observed data and current EM state via Gaussian process regression. This is by contrast with earlier approaches, where selection functions were manually-designed for each problem setting. We show that our approach performs as well as these bespoke selection functions on a wide variety of inference problems: in particular, for the challenging case of a hierarchical model for object localization with occlusion, we achieve results that match a customized state-of-the-art selection method, at a far lower computational cost.
A Truncated EM Approach for Spike-and-Slab Sparse Coding
Sep 03, 2014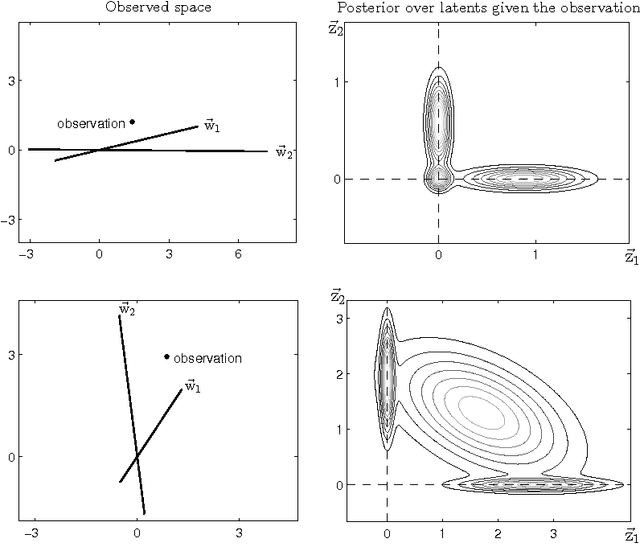



We study inference and learning based on a sparse coding model with `spike-and-slab' prior. As in standard sparse coding, the model used assumes independent latent sources that linearly combine to generate data points. However, instead of using a standard sparse prior such as a Laplace distribution, we study the application of a more flexible `spike-and-slab' distribution which models the absence or presence of a source's contribution independently of its strength if it contributes. We investigate two approaches to optimize the parameters of spike-and-slab sparse coding: a novel truncated EM approach and, for comparison, an approach based on standard factored variational distributions. The truncated approach can be regarded as a variational approach with truncated posteriors as variational distributions. In applications to source separation we find that both approaches improve the state-of-the-art in a number of standard benchmarks, which argues for the use of `spike-and-slab' priors for the corresponding data domains. Furthermore, we find that the truncated EM approach improves on the standard factored approach in source separation tasks$-$which hints to biases introduced by assuming posterior independence in the factored variational approach. Likewise, on a standard benchmark for image denoising, we find that the truncated EM approach improves on the factored variational approach. While the performance of the factored approach saturates with increasing numbers of hidden dimensions, the performance of the truncated approach improves the state-of-the-art for higher noise levels.
* To appear in JMLR (2014)