 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow robust accuracy suffers from certified training with convex relaxations
Jun 12, 2023



Adversarial attacks pose significant threats to deploying state-of-the-art classifiers in safety-critical applications. Two classes of methods have emerged to address this issue: empirical defences and certified defences. Although certified defences come with robustness guarantees, empirical defences such as adversarial training enjoy much higher popularity among practitioners. In this paper, we systematically compare the standard and robust error of these two robust training paradigms across multiple computer vision tasks. We show that in most tasks and for both $\mathscr{l}_\infty$-ball and $\mathscr{l}_2$-ball threat models, certified training with convex relaxations suffers from worse standard and robust error than adversarial training. We further explore how the error gap between certified and adversarial training depends on the threat model and the data distribution. In particular, besides the perturbation budget, we identify as important factors the shape of the perturbation set and the implicit margin of the data distribution. We support our arguments with extensive ablations on both synthetic and image datasets.
Uniform versus uncertainty sampling: When being active is less efficient than staying passive
Dec 01, 2022It is widely believed that given the same labeling budget, active learning algorithms like uncertainty sampling achieve better predictive performance than passive learning (i.e. uniform sampling), albeit at a higher computational cost. Recent empirical evidence suggests that this added cost might be in vain, as uncertainty sampling can sometimes perform even worse than passive learning. While existing works offer different explanations in the low-dimensional regime, this paper shows that the underlying mechanism is entirely different in high dimensions: we prove for logistic regression that passive learning outperforms uncertainty sampling even for noiseless data and when using the uncertainty of the Bayes optimal classifier. Insights from our proof indicate that this high-dimensional phenomenon is exacerbated when the separation between the classes is small. We corroborate this intuition with experiments on 20 high-dimensional datasets spanning a diverse range of applications, from finance and histology to chemistry and computer vision.
Why adversarial training can hurt robust accuracy
Mar 03, 2022
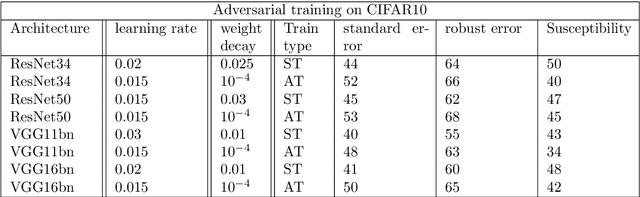


Machine learning classifiers with high test accuracy often perform poorly under adversarial attacks. It is commonly believed that adversarial training alleviates this issue. In this paper, we demonstrate that, surprisingly, the opposite may be true -- Even though adversarial training helps when enough data is available, it may hurt robust generalization in the small sample size regime. We first prove this phenomenon for a high-dimensional linear classification setting with noiseless observations. Our proof provides explanatory insights that may also transfer to feature learning models. Further, we observe in experiments on standard image datasets that the same behavior occurs for perceptible attacks that effectively reduce class information such as mask attacks and object corruptions.