 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Visualization of Aggregated Class Activation Maps to Analyse the Global Contribution of Class Features
Jul 29, 2023Deep learning (DL) models achieve remarkable performance in classification tasks. However, models with high complexity can not be used in many risk-sensitive applications unless a comprehensible explanation is presented. Explainable artificial intelligence (xAI) focuses on the research to explain the decision-making of AI systems like DL. We extend a recent method of Class Activation Maps (CAMs) which visualizes the importance of each feature of a data sample contributing to the classification. In this paper, we aggregate CAMs from multiple samples to show a global explanation of the classification for semantically structured data. The aggregation allows the analyst to make sophisticated assumptions and analyze them with further drill-down visualizations. Our visual representation for the global CAM illustrates the impact of each feature with a square glyph containing two indicators. The color of the square indicates the classification impact of this feature. The size of the filled square describes the variability of the impact between single samples. For interesting features that require further analysis, a detailed view is necessary that provides the distribution of these values. We propose an interactive histogram to filter samples and refine the CAM to show relevant samples only. Our approach allows an analyst to detect important features of high-dimensional data and derive adjustments to the AI model based on our global explanation visualization.
Extension of Dictionary-Based Compression Algorithms for the Quantitative Visualization of Patterns from Log Files
Apr 10, 2023Many services today massively and continuously produce log files of different and varying formats. These logs are important since they contain information about the application activities, which is necessary for improvements by analyzing the behavior and maintaining the security and stability of the system. It is a common practice to store log files in a compressed form to reduce the sheer size of these files. A compression algorithm identifies frequent patterns in a log file to remove redundant information. This work presents an approach to detect frequent patterns in textual data that can be simultaneously registered during the file compression process with low consumption of resources. The log file can be visualized with the possibility to explore the extracted patterns using metrics based on such properties as frequency, length and root prefixes of the acquired pattern. This allows an analyst to gain the relevant insights more efficiently reducing the need for manual labor-intensive inspection in the log data. The extension of the implemented dictionary-based compression algorithm has the advantage of recognizing patterns in log files of any format and eliminates the need to manually perform preparation for any preprocessing of log files.
Visualization Of Class Activation Maps To Explain AI Classification Of Network Packet Captures
Sep 05, 2022
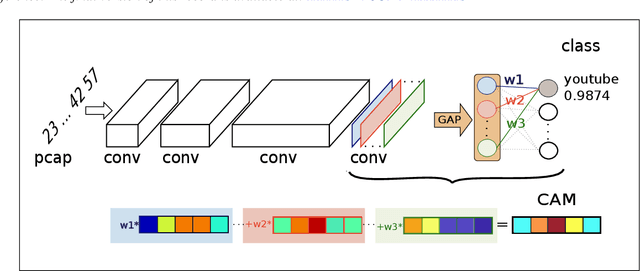
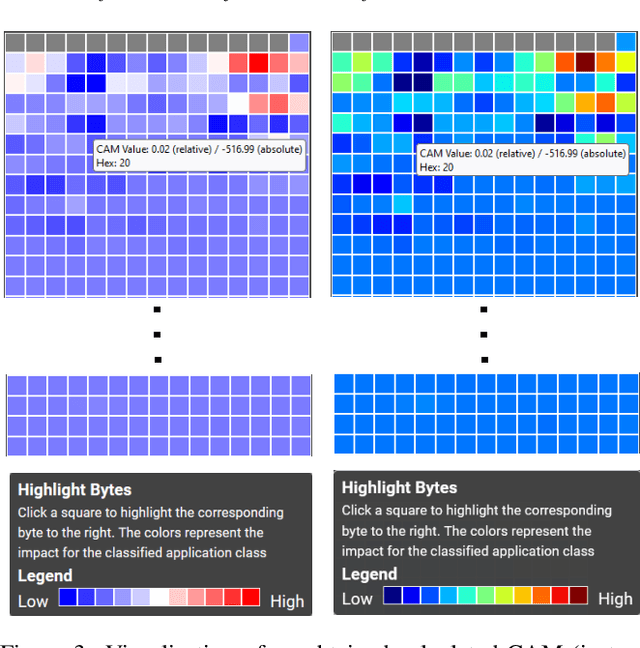
The classification of internet traffic has become increasingly important due to the rapid growth of today's networks and applications. The number of connections and the addition of new applications in our networks causes a vast amount of log data and complicates the search for common patterns by experts. Finding such patterns among specific classes of applications is necessary to fulfill various requirements in network analytics. Deep learning methods provide both feature extraction and classification from data in a single system. However, these networks are very complex and are used as black-box models, which weakens the experts' trust in the classifications. Moreover, by using them as a black-box, new knowledge cannot be obtained from the model predictions despite their excellent performance. Therefore, the explainability of the classifications is crucial. Besides increasing trust, the explanation can be used for model evaluation gaining new insights from the data and improving the model. In this paper, we present a visual interactive tool that combines the classification of network data with an explanation technique to form an interface between experts, algorithms, and data.
Visual-Interactive Similarity Search for Complex Objects by Example of Soccer Player Analysis
Mar 09, 2017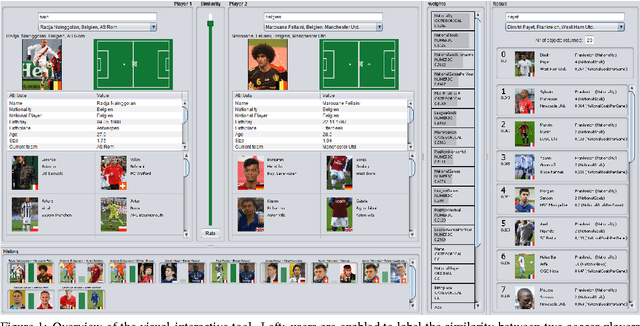
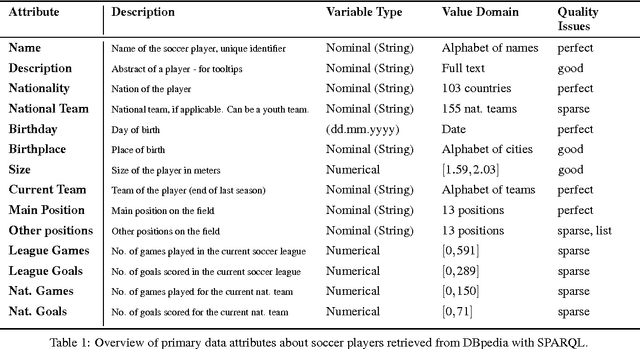
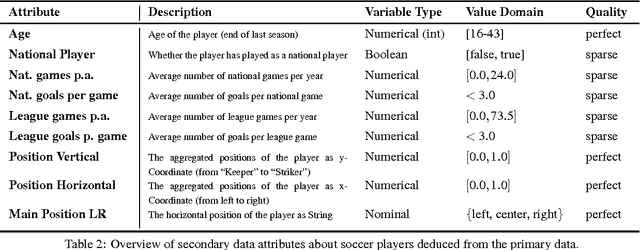
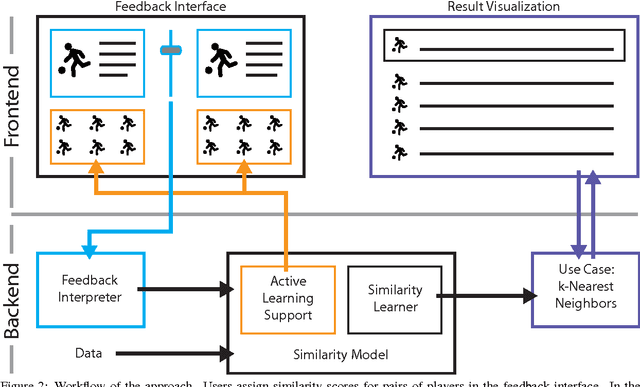
The definition of similarity is a key prerequisite when analyzing complex data types in data mining, information retrieval, or machine learning. However, the meaningful definition is often hampered by the complexity of data objects and particularly by different notions of subjective similarity latent in targeted user groups. Taking the example of soccer players, we present a visual-interactive system that learns users' mental models of similarity. In a visual-interactive interface, users are able to label pairs of soccer players with respect to their subjective notion of similarity. Our proposed similarity model automatically learns the respective concept of similarity using an active learning strategy. A visual-interactive retrieval technique is provided to validate the model and to execute downstream retrieval tasks for soccer player analysis. The applicability of the approach is demonstrated in different evaluation strategies, including usage scenarions and cross-validation tests.