 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reference Model for Collaborative Business Intelligence Virtual Assistants
Apr 20, 2023Collaborative Business Analysis (CBA) is a methodology that involves bringing together different stakeholders, including business users, analysts, and technical specialists, to collaboratively analyze data and gain insights into business operations. The primary objective of CBA is to encourage knowledge sharing and collaboration between the different groups involved in business analysis, as this can lead to a more comprehensive understanding of the data and better decision-making. CBA typically involves a range of activities, including data gathering and analysis, brainstorming, problem-solving, decision-making and knowledge sharing. These activities may take place through various channels, such as in-person meetings, virtual collaboration tools or online forums. This paper deals with virtual collaboration tools as an important part of Business Intelligence (BI) platform. Collaborative Business Intelligence (CBI) tools are becoming more user-friendly, accessible, and flexible, allowing users to customize their experience and adapt to their specific needs. The goal of a virtual assistant is to make data exploration more accessible to a wider range of users and to reduce the time and effort required for data analysis. It describes the unified business intelligence semantic model, coupled with a data warehouse and collaborative unit to employ data mining technology. Moreover, we propose a virtual assistant for CBI and a reference model of virtual tools for CBI, which consists of three components: conversational, data exploration and recommendation agents. We believe that the allocation of these three functional tasks allows you to structure the CBI issue and apply relevant and productive models for human-like dialogue, text-to-command transferring, and recommendations simultaneously. The complex approach based on these three points gives the basis for virtual tool for collaboration. CBI encourages people, processes, and technology to enable everyone sharing and leveraging collective expertise, knowledge and data to gain valuable insights for making better decisions. This allows to respond more quickly and effectively to changes in the market or internal operations and improve the progress.
Calling to CNN-LSTM for Rumor Detection: A Deep Multi-channel Model for Message Veracity Classification in Microblogs
Oct 11, 2021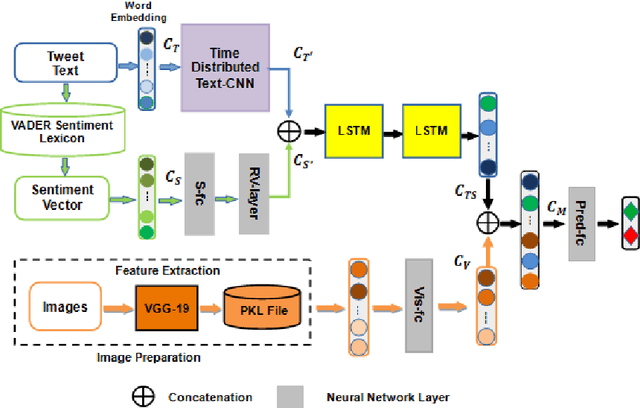
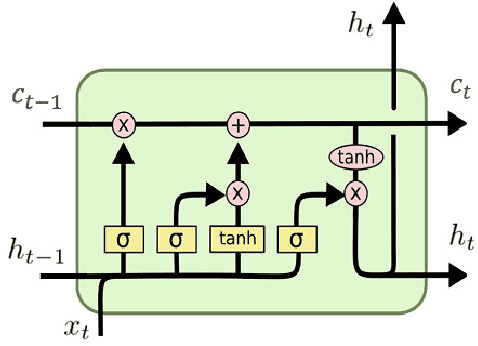

Reputed by their low-cost, easy-access, real-time and valuable information, social media also wildly spread unverified or fake news. Rumors can notably cause severe damage on individuals and the society. Therefore, rumor detection on social media has recently attracted tremendous attention. Most rumor detection approaches focus on rumor feature analysis and social features, i.e., metadata in social media. Unfortunately, these features are data-specific and may not always be available, e.g., when the rumor has just popped up and not yet propagated. In contrast, post contents (including images or videos) play an important role and can indicate the diffusion purpose of a rumor. Furthermore, rumor classification is also closely related to opinion mining and sentiment analysis. Yet, to the best of our knowledge, exploiting images and sentiments is little investigated.Considering the available multimodal features from microblogs, notably, we propose in this paper an end-to-end model called deepMONITOR that is based on deep neural networks and allows quite accurate automated rumor verification, by utilizing all three characteristics: post textual and image contents, as well as sentiment. deepMONITOR concatenates image features with the joint text and sentiment features to produce a reliable, fused classification. We conduct extensive experiments on two large-scale, real-world datasets. The results show that deepMONITOR achieves a higher accuracy than state-of-the-art methods.
MONITOR: A Multimodal Fusion Framework to Assess Message Veracity in Social Networks
Sep 06, 2021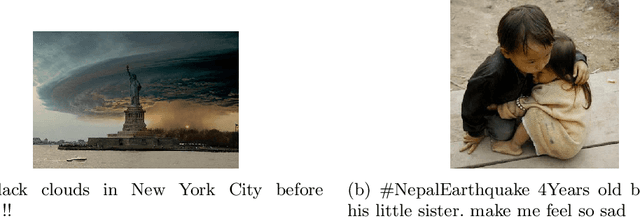
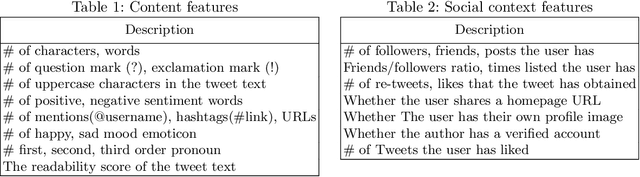


Users of social networks tend to post and share content with little restraint. Hence, rumors and fake news can quickly spread on a huge scale. This may pose a threat to the credibility of social media and can cause serious consequences in real life. Therefore, the task of rumor detection and verification has become extremely important. Assessing the veracity of a social media message (e.g., by fact checkers) involves analyzing the text of the message, its context and any multimedia attachment. This is a very time-consuming task that can be much helped by machine learning. In the literature, most message veracity verification methods only exploit textual contents and metadata. Very few take both textual and visual contents, and more particularly images, into account. In this paper, we second the hypothesis that exploiting all of the components of a social media post enhances the accuracy of veracity detection. To further the state of the art, we first propose using a set of advanced image features that are inspired from the field of image quality assessment, which effectively contributes to rumor detection. These metrics are good indicators for the detection of fake images, even for those generated by advanced techniques like generative adversarial networks (GANs). Then, we introduce the Multimodal fusiON framework to assess message veracIty in social neTwORks (MONITOR), which exploits all message features (i.e., text, social context, and image features) by supervised machine learning. Such algorithms provide interpretability and explainability in the decisions taken, which we believe is particularly important in the context of rumor verification. Experimental results show that MONITOR can detect rumors with an accuracy of 96% and 89% on the MediaEval benchmark and the FakeNewsNet dataset, respectively. These results are significantly better than those of state-of-the-art machine learning baselines.
Including Images into Message Veracity Assessment in Social Media
Jul 20, 2020
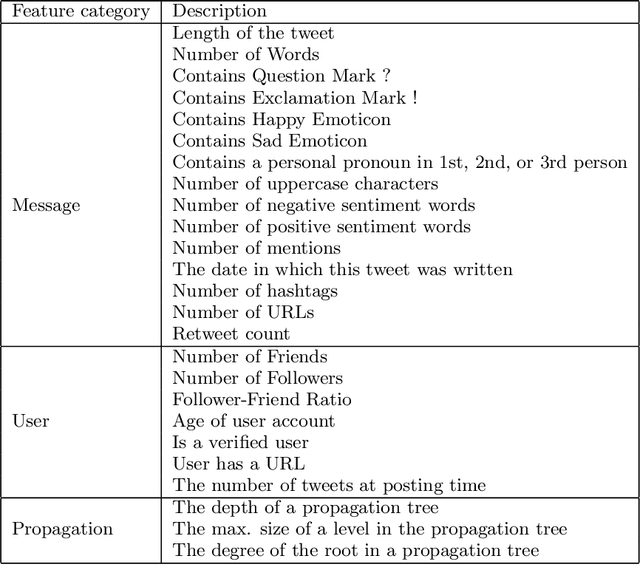
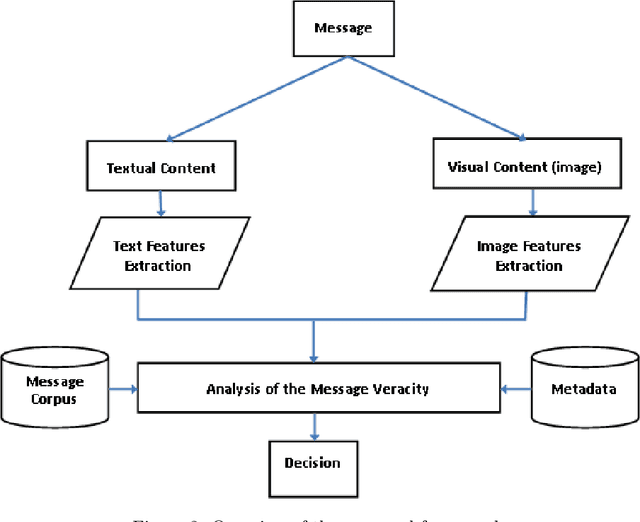

The extensive use of social media in the diffusion of information has also laid a fertile ground for the spread of rumors, which could significantly affect the credibility of social media. An ever-increasing number of users post news including, in addition to text, multimedia data such as images and videos. Yet, such multimedia content is easily editable due to the broad availability of simple and effective image and video processing tools. The problem of assessing the veracity of social network posts has attracted a lot of attention from researchers in recent years. However, almost all previous works have focused on analyzing textual contents to determine veracity, while visual contents, and more particularly images, remains ignored or little exploited in the literature. In this position paper, we propose a framework that explores two novel ways to assess the veracity of messages published on social networks by analyzing the credibility of both their textual and visual contents.
MaxMin Linear Initialization for Fuzzy C-Means
Aug 01, 2018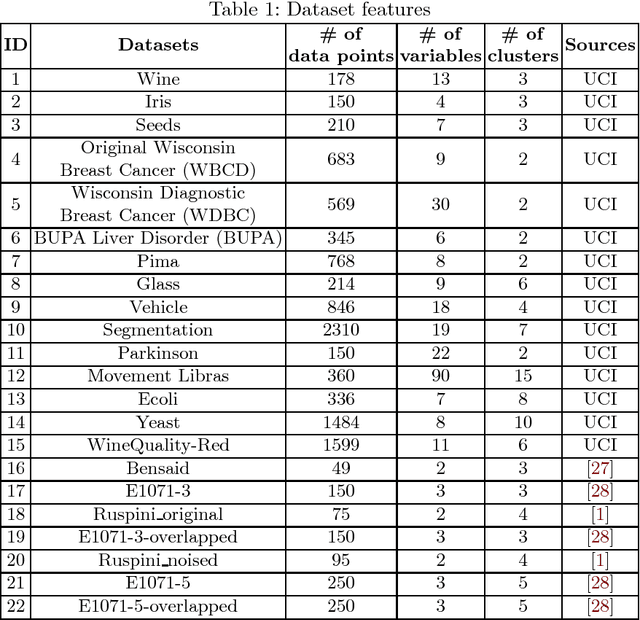
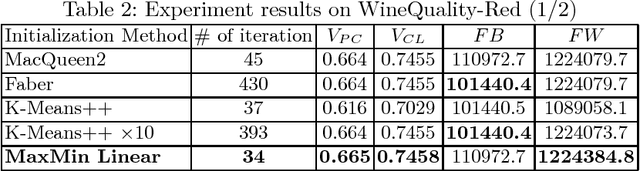
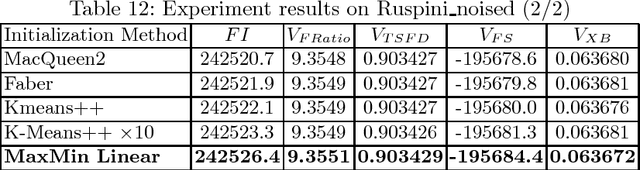
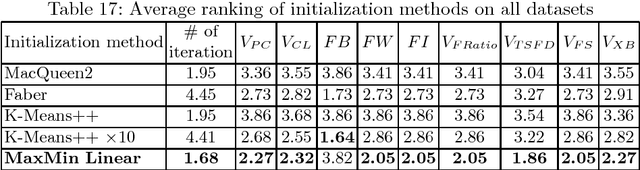
Clustering is an extensive research area in data science. The aim of clustering is to discover groups and to identify interesting patterns in datasets. Crisp (hard) clustering considers that each data point belongs to one and only one cluster. However, it is inadequate as some data points may belong to several clusters, as is the case in text categorization. Thus, we need more flexible clustering. Fuzzy clustering methods, where each data point can belong to several clusters, are an interesting alternative. Yet, seeding iterative fuzzy algorithms to achieve high quality clustering is an issue. In this paper, we propose a new linear and efficient initialization algorithm MaxMin Linear to deal with this problem. Then, we validate our theoretical results through extensive experiments on a variety of numerical real-world and artificial datasets. We also test several validity indices, including a new validity index that we propose, Transformed Standardized Fuzzy Difference (TSFD).
A Visual Quality Index for Fuzzy C-Means
Jun 05, 2018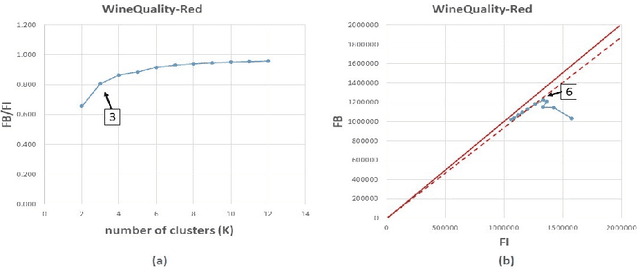
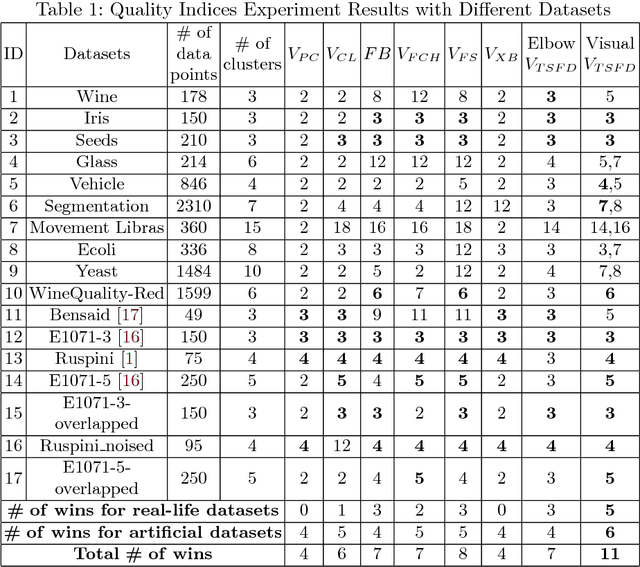
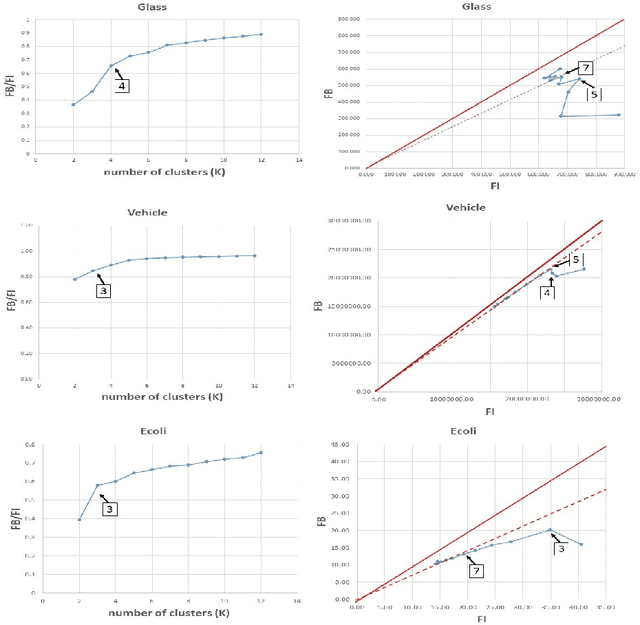
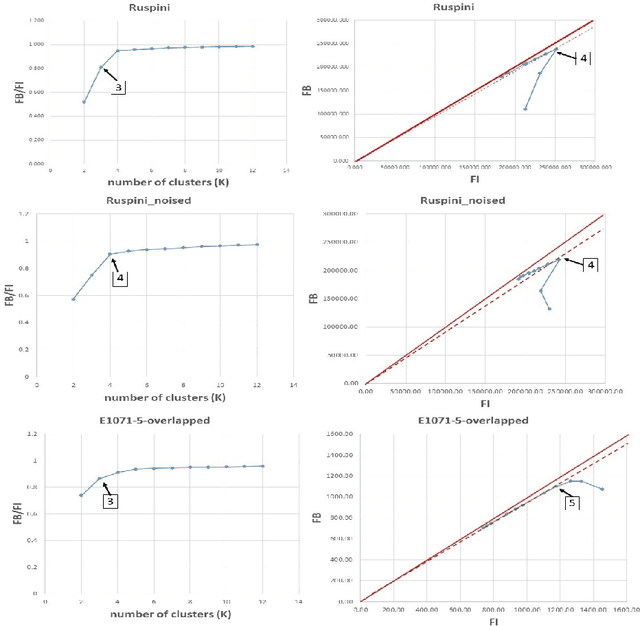
Cluster analysis is widely used in the areas of machine learning and data mining. Fuzzy clustering is a particular method that considers that a data point can belong to more than one cluster. Fuzzy clustering helps obtain flexible clusters, as needed in such applications as text categorization. The performance of a clustering algorithm critically depends on the number of clusters, and estimating the optimal number of clusters is a challenging task. Quality indices help estimate the optimal number of clusters. However, there is no quality index that can obtain an accurate number of clusters for different datasets. Thence, in this paper, we propose a new cluster quality index associated with a visual, graph-based solution that helps choose the optimal number of clusters in fuzzy partitions. Moreover, we validate our theoretical results through extensive comparison experiments against state-of-the-art quality indices on a variety of numerical real-world and artificial datasets.