 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaxMin Linear Initialization for Fuzzy C-Means
Aug 01, 2018
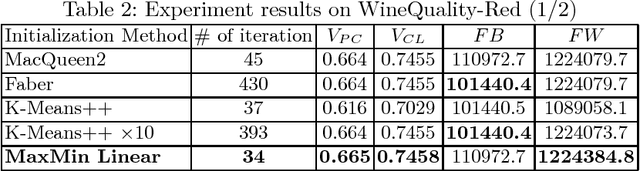
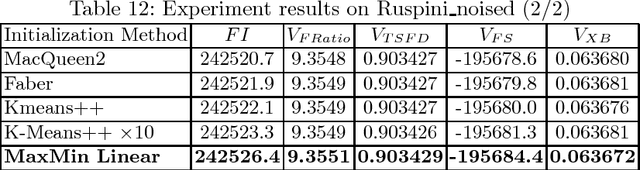
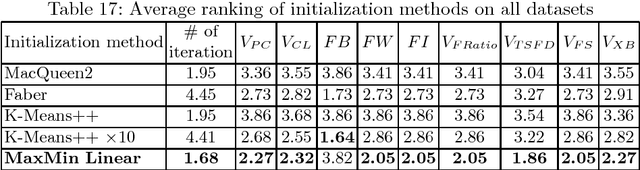
Clustering is an extensive research area in data science. The aim of clustering is to discover groups and to identify interesting patterns in datasets. Crisp (hard) clustering considers that each data point belongs to one and only one cluster. However, it is inadequate as some data points may belong to several clusters, as is the case in text categorization. Thus, we need more flexible clustering. Fuzzy clustering methods, where each data point can belong to several clusters, are an interesting alternative. Yet, seeding iterative fuzzy algorithms to achieve high quality clustering is an issue. In this paper, we propose a new linear and efficient initialization algorithm MaxMin Linear to deal with this problem. Then, we validate our theoretical results through extensive experiments on a variety of numerical real-world and artificial datasets. We also test several validity indices, including a new validity index that we propose, Transformed Standardized Fuzzy Difference (TSFD).
A Visual Quality Index for Fuzzy C-Means
Jun 05, 2018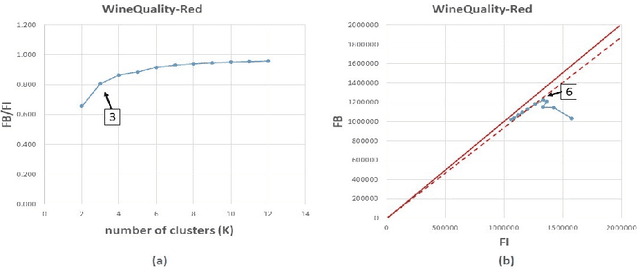
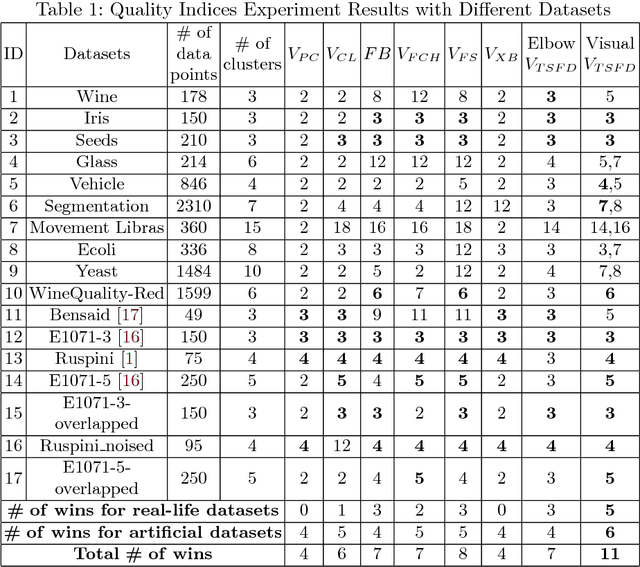
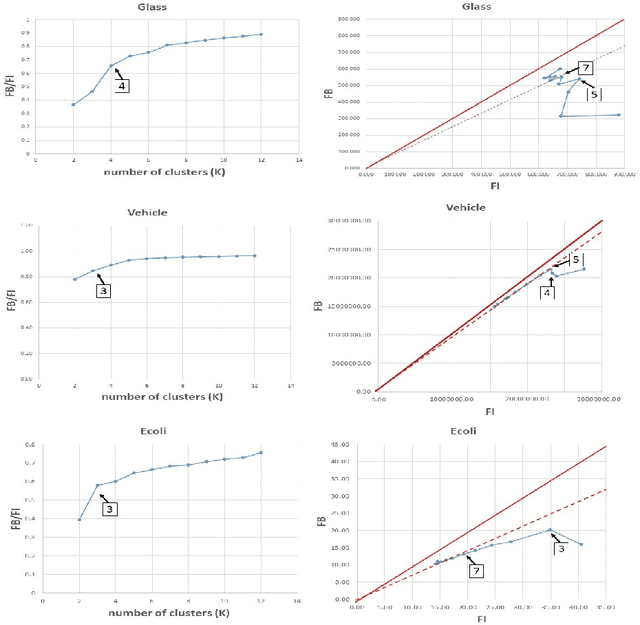
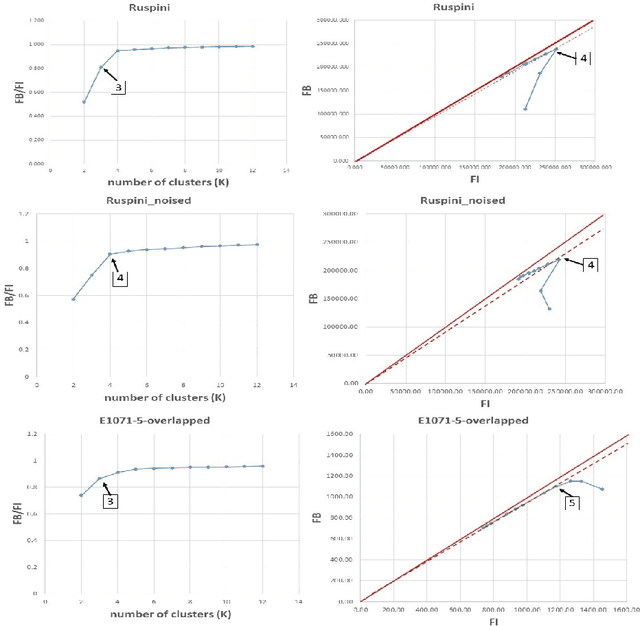
Cluster analysis is widely used in the areas of machine learning and data mining. Fuzzy clustering is a particular method that considers that a data point can belong to more than one cluster. Fuzzy clustering helps obtain flexible clusters, as needed in such applications as text categorization. The performance of a clustering algorithm critically depends on the number of clusters, and estimating the optimal number of clusters is a challenging task. Quality indices help estimate the optimal number of clusters. However, there is no quality index that can obtain an accurate number of clusters for different datasets. Thence, in this paper, we propose a new cluster quality index associated with a visual, graph-based solution that helps choose the optimal number of clusters in fuzzy partitions. Moreover, we validate our theoretical results through extensive comparison experiments against state-of-the-art quality indices on a variety of numerical real-world and artificial datasets.