 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaxMin Linear Initialization for Fuzzy C-Means
Aug 01, 2018
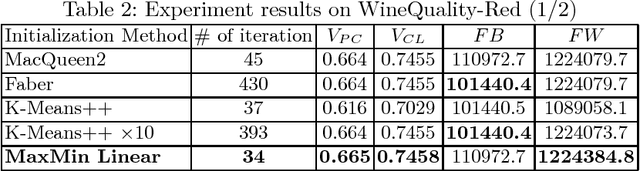
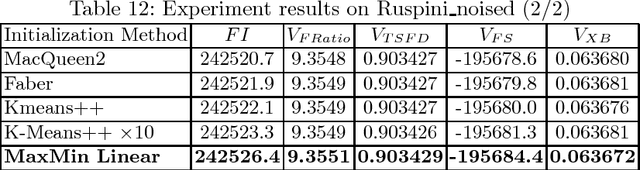
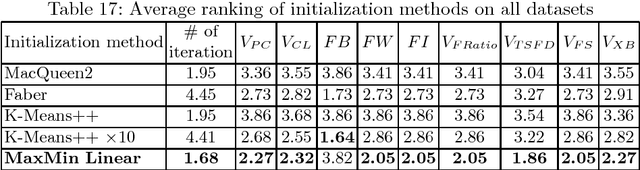
Clustering is an extensive research area in data science. The aim of clustering is to discover groups and to identify interesting patterns in datasets. Crisp (hard) clustering considers that each data point belongs to one and only one cluster. However, it is inadequate as some data points may belong to several clusters, as is the case in text categorization. Thus, we need more flexible clustering. Fuzzy clustering methods, where each data point can belong to several clusters, are an interesting alternative. Yet, seeding iterative fuzzy algorithms to achieve high quality clustering is an issue. In this paper, we propose a new linear and efficient initialization algorithm MaxMin Linear to deal with this problem. Then, we validate our theoretical results through extensive experiments on a variety of numerical real-world and artificial datasets. We also test several validity indices, including a new validity index that we propose, Transformed Standardized Fuzzy Difference (TSFD).
A Visual Quality Index for Fuzzy C-Means
Jun 05, 2018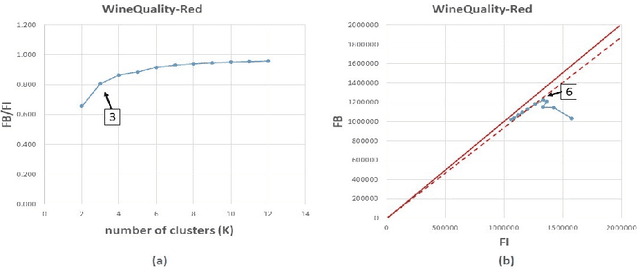
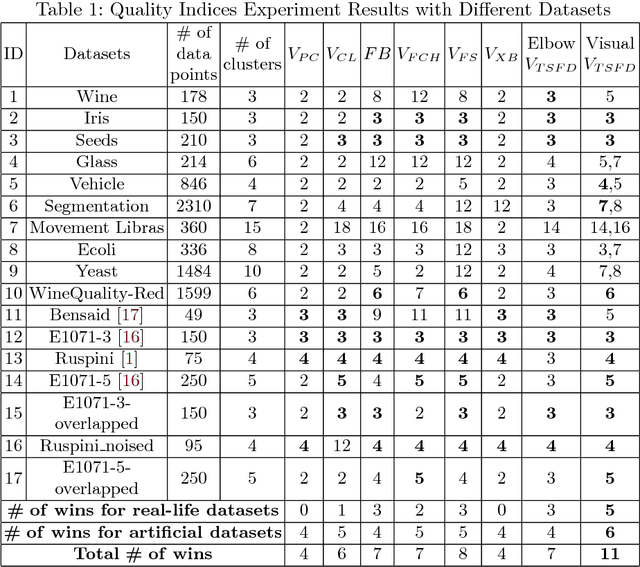
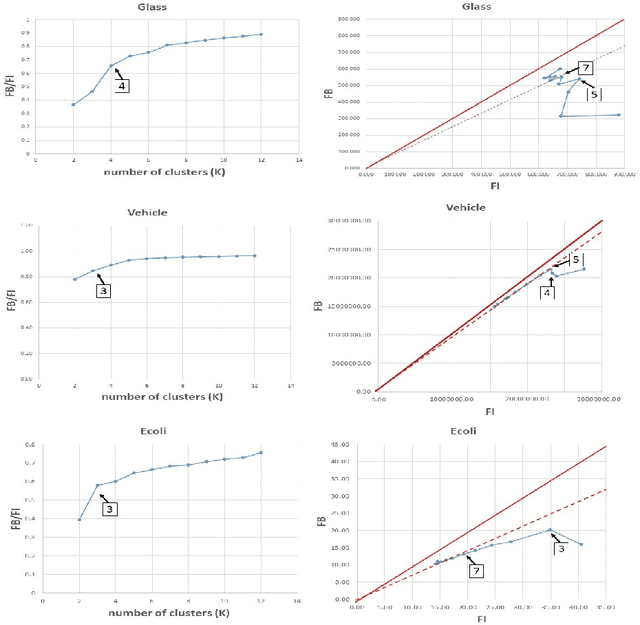
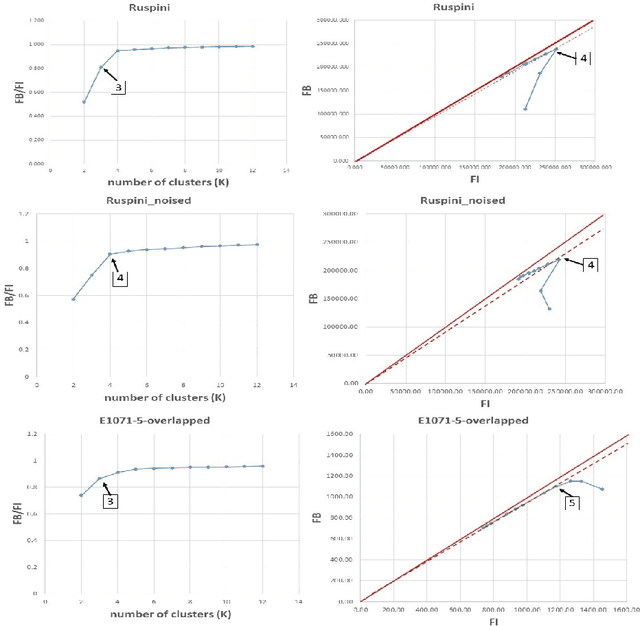
Cluster analysis is widely used in the areas of machine learning and data mining. Fuzzy clustering is a particular method that considers that a data point can belong to more than one cluster. Fuzzy clustering helps obtain flexible clusters, as needed in such applications as text categorization. The performance of a clustering algorithm critically depends on the number of clusters, and estimating the optimal number of clusters is a challenging task. Quality indices help estimate the optimal number of clusters. However, there is no quality index that can obtain an accurate number of clusters for different datasets. Thence, in this paper, we propose a new cluster quality index associated with a visual, graph-based solution that helps choose the optimal number of clusters in fuzzy partitions. Moreover, we validate our theoretical results through extensive comparison experiments against state-of-the-art quality indices on a variety of numerical real-world and artificial datasets.
How to Use Temporal-Driven Constrained Clustering to Detect Typical Evolutions
Jan 11, 2016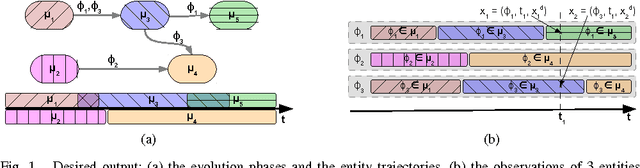
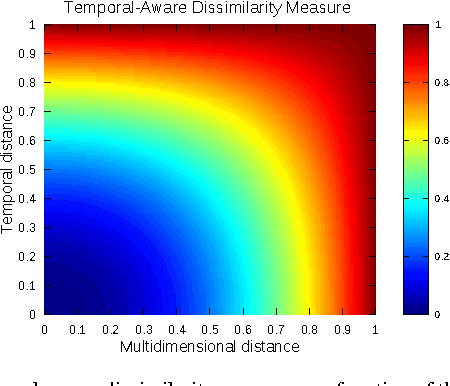
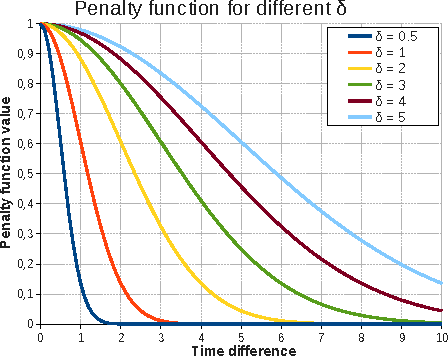
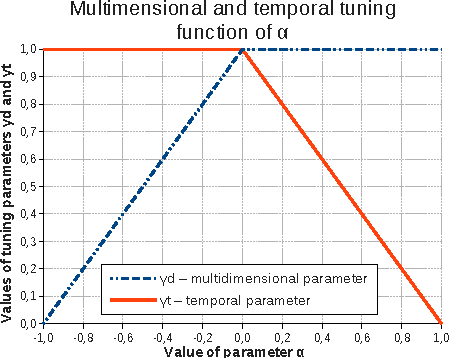
In this paper, we propose a new time-aware dissimilarity measure that takes into account the temporal dimension. Observations that are close in the description space, but distant in time are considered as dissimilar. We also propose a method to enforce the segmentation contiguity, by introducing, in the objective function, a penalty term inspired from the Normal Distribution Function. We combine the two propositions into a novel time-driven constrained clustering algorithm, called TDCK-Means, which creates a partition of coherent clusters, both in the multidimensional space and in the temporal space. This algorithm uses soft semi-supervised constraints, to encourage adjacent observations belonging to the same entity to be assigned to the same cluster. We apply our algorithm to a Political Studies dataset in order to detect typical evolution phases. We adapt the Shannon entropy in order to measure the entity contiguity, and we show that our proposition consistently improves temporal cohesion of clusters, without any significant loss in the multidimensional variance.
Unsupervised Feature Construction for Improving Data Representation and Semantics
Dec 17, 2015

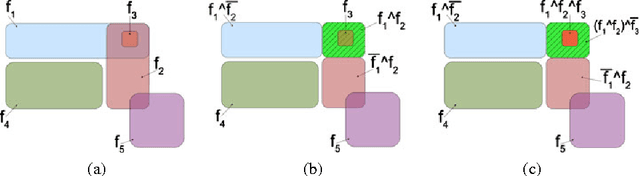

Feature-based format is the main data representation format used by machine learning algorithms. When the features do not properly describe the initial data, performance starts to degrade. Some algorithms address this problem by internally changing the representation space, but the newly-constructed features are rarely comprehensible. We seek to construct, in an unsupervised way, new features that are more appropriate for describing a given dataset and, at the same time, comprehensible for a human user. We propose two algorithms that construct the new features as conjunctions of the initial primitive features or their negations. The generated feature sets have reduced correlations between features and succeed in catching some of the hidden relations between individuals in a dataset. For example, a feature like $sky \wedge \neg building \wedge panorama$ would be true for non-urban images and is more informative than simple features expressing the presence or the absence of an object. The notion of Pareto optimality is used to evaluate feature sets and to obtain a balance between total correlation and the complexity of the resulted feature set. Statistical hypothesis testing is used in order to automatically determine the values of the parameters used for constructing a data-dependent feature set. We experimentally show that our approaches achieve the construction of informative feature sets for multiple datasets.
Semantic-enriched Visual Vocabulary Construction in a Weakly Supervised Context
Dec 14, 2015


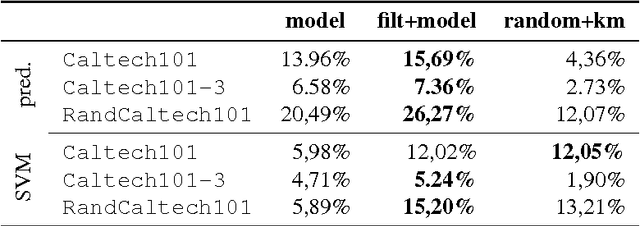
One of the prevalent learning tasks involving images is content-based image classification. This is a difficult task especially because the low-level features used to digitally describe images usually capture little information about the semantics of the images. In this paper, we tackle this difficulty by enriching the semantic content of the image representation by using external knowledge. The underlying hypothesis of our work is that creating a more semantically rich representation for images would yield higher machine learning performances, without the need to modify the learning algorithms themselves. The external semantic information is presented under the form of non-positional image labels, therefore positioning our work in a weakly supervised context. Two approaches are proposed: the first one leverages the labels into the visual vocabulary construction algorithm, the result being dedicated visual vocabularies. The second approach adds a filtering phase as a pre-processing of the vocabulary construction. Known positive and known negative sets are constructed and features that are unlikely to be associated with the objects denoted by the labels are filtered. We apply our proposition to the task of content-based image classification and we show that semantically enriching the image representation yields higher classification performances than the baseline representation.