 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Scope, with Application to Information Extraction and Classification
Dec 12, 2012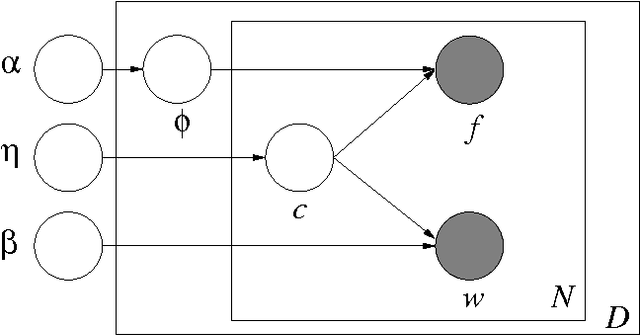


In probabilistic approaches to classification and information extraction, one typically builds a statistical model of words under the assumption that future data will exhibit the same regularities as the training data. In many data sets, however, there are scope-limited features whose predictive power is only applicable to a certain subset of the data. For example, in information extraction from web pages, word formatting may be indicative of extraction category in different ways on different web pages. The difficulty with using such features is capturing and exploiting the new regularities encountered in previously unseen data. In this paper, we propose a hierarchical probabilistic model that uses both local/scope-limited features, such as word formatting, and global features, such as word content. The local regularities are modeled as an unobserved random parameter which is drawn once for each local data set. This random parameter is estimated during the inference process and then used to perform classification with both the local and global features--- a procedure which is akin to automatically retuning the classifier to the local regularities on each newly encountered web page. Exact inference is intractable and we present approximations via point estimates and variational methods. Empirical results on large collections of web data demonstrate that this method significantly improves performance from traditional models of global features alone.
Learning Selectively Conditioned Forest Structures with Applications to DBNs and Classification
Jun 20, 2012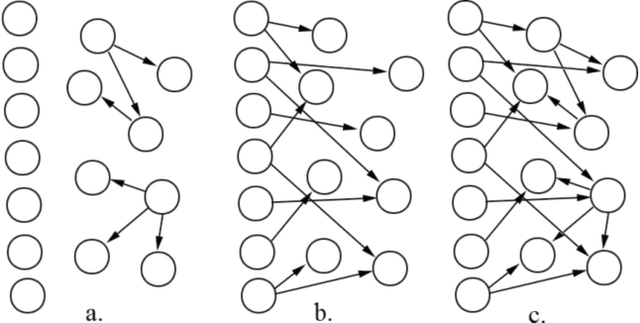
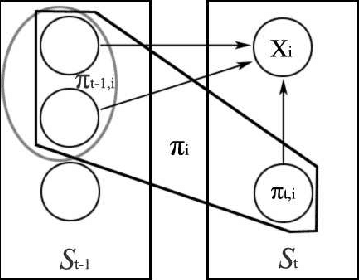
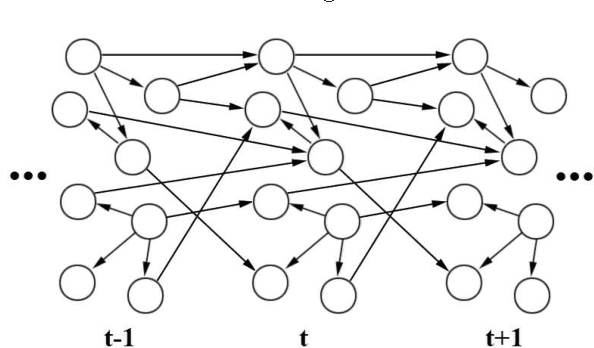
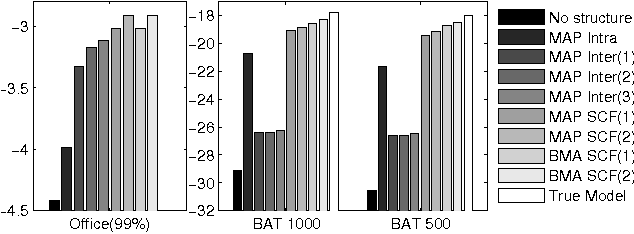
Dealing with uncertainty in Bayesian Network structures using maximum a posteriori (MAP) estimation or Bayesian Model Averaging (BMA) is often intractable due to the superexponential number of possible directed, acyclic graphs. When the prior is decomposable, two classes of graphs where efficient learning can take place are tree structures, and fixed-orderings with limited in-degree. We show how MAP estimates and BMA for selectively conditioned forests (SCF), a combination of these two classes, can be computed efficiently for ordered sets of variables. We apply SCFs to temporal data to learn Dynamic Bayesian Networks having an intra-timestep forest and inter-timestep limited in-degree structure, improving model accuracy over DBNs without the combination of structures. We also apply SCFs to Bayes Net classification to learn selective forest augmented Naive Bayes classifiers. We argue that the built-in feature selection of selective augmented Bayes classifiers makes them preferable to similar non-selective classifiers based on empirical evidence.
Convex Coding
May 09, 2012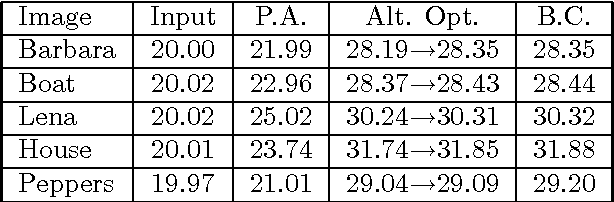
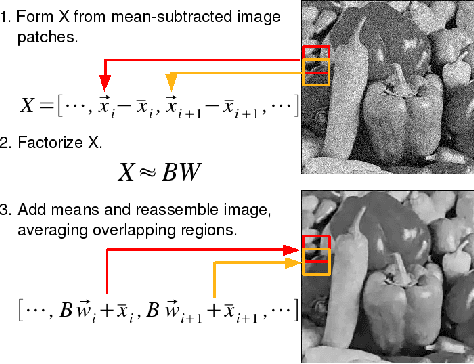


Inspired by recent work on convex formulations of clustering (Lashkari & Golland, 2008; Nowozin & Bakir, 2008) we investigate a new formulation of the Sparse Coding Problem (Olshausen & Field, 1997). In sparse coding we attempt to simultaneously represent a sequence of data-vectors sparsely (i.e. sparse approximation (Tropp et al., 2006)) in terms of a 'code' defined by a set of basis elements, while also finding a code that enables such an approximation. As existing alternating optimization procedures for sparse coding are theoretically prone to severe local minima problems, we propose a convex relaxation of the sparse coding problem and derive a boosting-style algorithm, that (Nowozin & Bakir, 2008) serves as a convex 'master problem' which calls a (potentially non-convex) sub-problem to identify the next code element to add. Finally, we demonstrate the properties of our boosted coding algorithm on an image denoising task.