 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Scope, with Application to Information Extraction and Classification
Paper and Code
Dec 12, 2012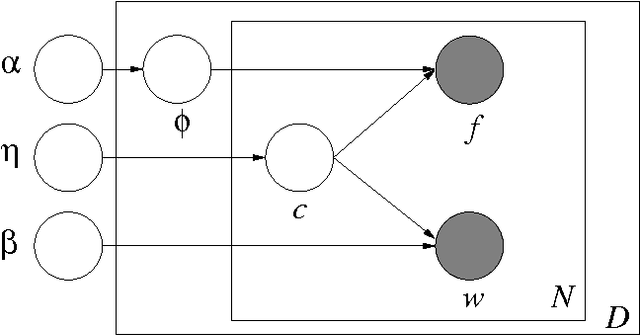


In probabilistic approaches to classification and information extraction, one typically builds a statistical model of words under the assumption that future data will exhibit the same regularities as the training data. In many data sets, however, there are scope-limited features whose predictive power is only applicable to a certain subset of the data. For example, in information extraction from web pages, word formatting may be indicative of extraction category in different ways on different web pages. The difficulty with using such features is capturing and exploiting the new regularities encountered in previously unseen data. In this paper, we propose a hierarchical probabilistic model that uses both local/scope-limited features, such as word formatting, and global features, such as word content. The local regularities are modeled as an unobserved random parameter which is drawn once for each local data set. This random parameter is estimated during the inference process and then used to perform classification with both the local and global features--- a procedure which is akin to automatically retuning the classifier to the local regularities on each newly encountered web page. Exact inference is intractable and we present approximations via point estimates and variational methods. Empirical results on large collections of web data demonstrate that this method significantly improves performance from traditional models of global features alone.