 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Coordinated Concurrent Reinforcement Learning
Jan 31, 2024In this work, we propose a novel algorithmic framework for data sharing and coordinated exploration for the purpose of learning more data-efficient and better performing policies under a concurrent reinforcement learning (CRL) setting. In contrast to other work which make the assumption that all agents act under identical environments, we relax this restriction and instead consider the formulation where each agent acts within an environment which shares a global structure but also exhibits individual variations. Our algorithm leverages a causal inference algorithm in the form of Additive Noise Model - Mixture Model (ANM-MM) in extracting model parameters governing individual differentials via independence enforcement. We propose a new data sharing scheme based on a similarity measure of the extracted model parameters and demonstrate superior learning speeds on a set of autoregressive, pendulum and cart-pole swing-up tasks and finally, we show the effectiveness of diverse action selection between common agents under a sparse reward setting. To the best of our knowledge, this is the first work in considering non-identical environments in CRL and one of the few works which seek to integrate causal inference with reinforcement learning (RL).
Adaptive Tree Backup Algorithms for Temporal-Difference Reinforcement Learning
Jun 04, 2022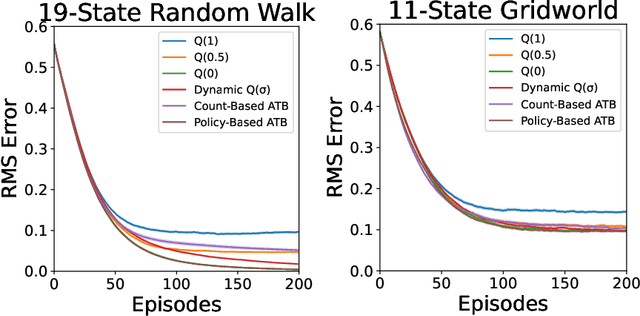
Q($\sigma$) is a recently proposed temporal-difference learning method that interpolates between learning from expected backups and sampled backups. It has been shown that intermediate values for the interpolation parameter $\sigma \in [0,1]$ perform better in practice, and therefore it is commonly believed that $\sigma$ functions as a bias-variance trade-off parameter to achieve these improvements. In our work, we disprove this notion, showing that the choice of $\sigma=0$ minimizes variance without increasing bias. This indicates that $\sigma$ must have some other effect on learning that is not fully understood. As an alternative, we hypothesize the existence of a new trade-off: larger $\sigma$-values help overcome poor initializations of the value function, at the expense of higher statistical variance. To automatically balance these considerations, we propose Adaptive Tree Backup (ATB) methods, whose weighted backups evolve as the agent gains experience. Our experiments demonstrate that adaptive strategies can be more effective than relying on fixed or time-annealed $\sigma$-values.