 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven audio recognition: a supervised dictionary approach
Dec 29, 2020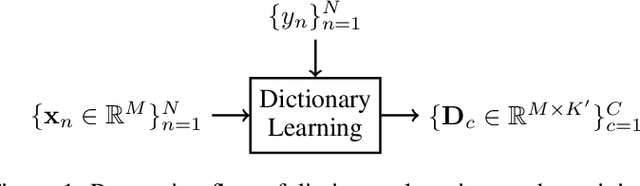
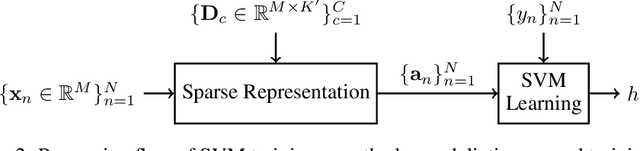
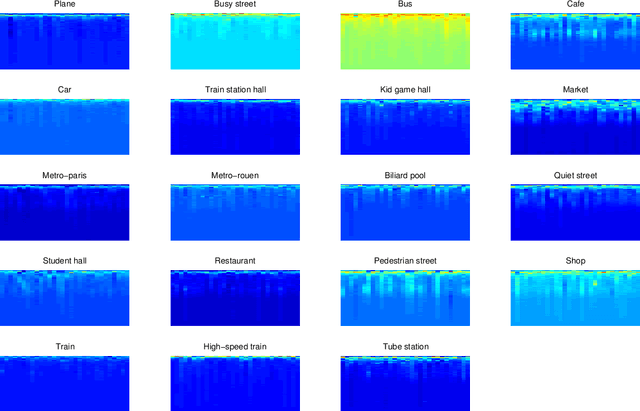
Machine hearing is an emerging area. Motivated by the need of a principled framework across domain applications for machine listening, we propose a generic and data-driven representation learning approach. For this sake, a novel and efficient supervised dictionary learning method is presented. Experiments are performed on both computational auditory scene (East Anglia and Rouen) and synthetic music chord recognition datasets. Obtained results show that our method is capable to reach state-of-the-art hand-crafted features for both applications
Towards Human Body-Part Learning for Model-Free Gait Recognition
Apr 02, 2019
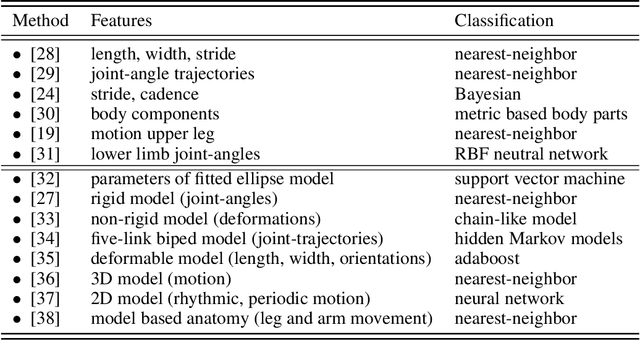
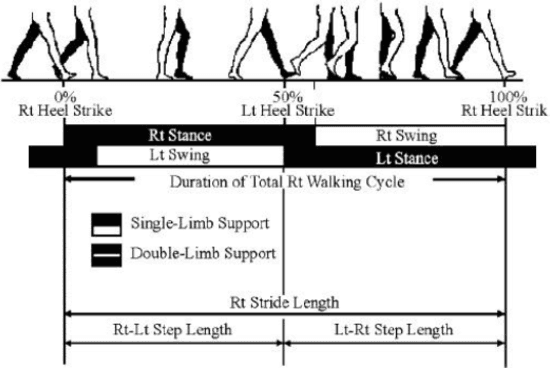
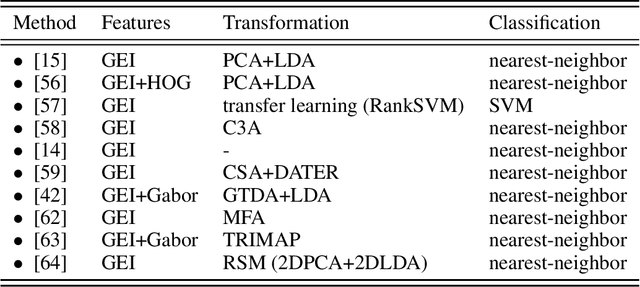
Gait based biometric aims to discriminate among people by the way or manner they walk. It represents a biometric at distance which has many advantages over other biometric modalities. State-of-the-art methods require a limited cooperation from the individuals. Consequently, contrary to other modalities, gait is a non-invasive approach. As a behavioral analysis, gait is difficult to circumvent. Moreover, gait can be performed without the subject being aware of it. Consequently, it is more difficult to try to tamper one own biometric signature. In this paper we review different features and approaches used in gait recognition. A novel method able to learn the discriminative human body-parts to improve the recognition accuracy will be introduced. Extensive experiments will be performed on CASIA gait benchmark database and results will be compared to state-of-the-art methods.
Forensic Shoe-print Identification: A Brief Survey
Jan 05, 2019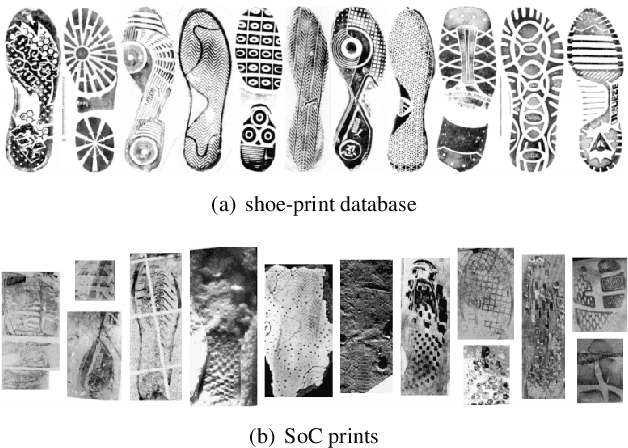
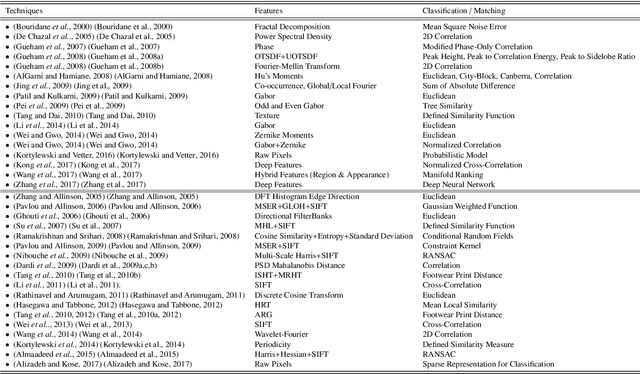
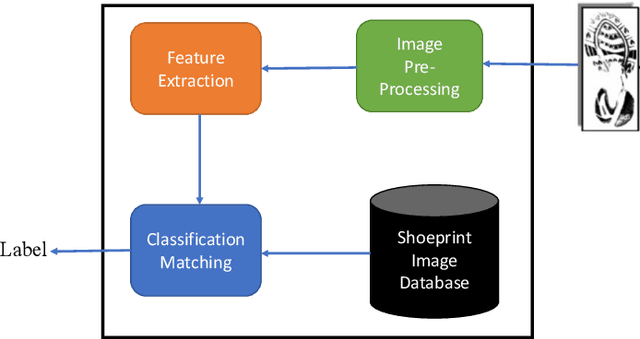
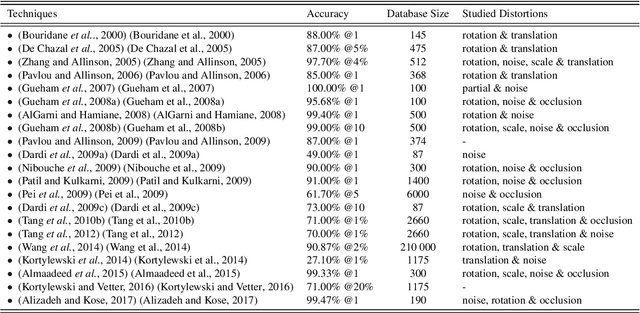
As an advanced research topic in forensics science, automatic shoe-print identification has been extensively studied in the last two decades, since shoe marks are the clues most frequently left in a crime scene. Hence, these impressions provide a pertinent evidence for the proper progress of investigations in order to identify the potential criminals. The main goal of this survey is to provide a cohesive overview of the research carried out in forensic shoe-print identification and its basic background. Apart defining the problem and describing the phases that typically compose the processing chain of shoe-print identification, we provide a summary/comparison of the state-of-the-art approaches, in order to guide the neophyte and help to advance the research topic. This is done through introducing simple and basic taxonomies as well as summaries of the state-of-the-art performance. Lastly, we discuss the current open problems and challenges in this research topic, point out for promising directions in this field.
An efficient supervised dictionary learning method for audio signal recognition
Dec 12, 2018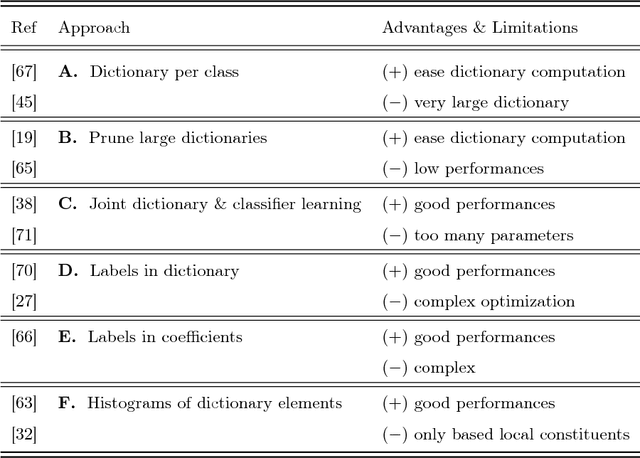
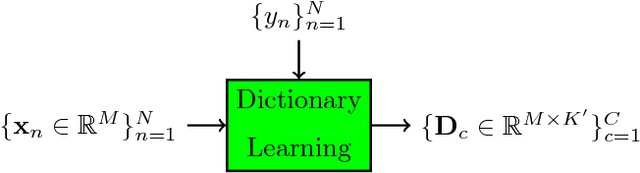
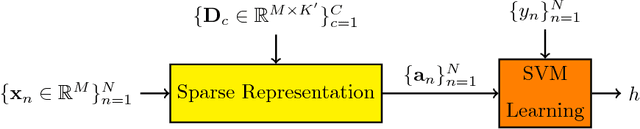
Machine hearing or listening represents an emerging area. Conventional approaches rely on the design of handcrafted features specialized to a specific audio task and that can hardly generalized to other audio fields. For example, Mel-Frequency Cepstral Coefficients (MFCCs) and its variants were successfully applied to computational auditory scene recognition while Chroma vectors are good at music chord recognition. Unfortunately, these predefined features may be of variable discrimination power while extended to other tasks or even within the same task due to different nature of clips. Motivated by this need of a principled framework across domain applications for machine listening, we propose a generic and data-driven representation learning approach. For this sake, a novel and efficient supervised dictionary learning method is presented. The method learns dissimilar dictionaries, one per each class, in order to extract heterogeneous information for classification. In other words, we are seeking to minimize the intra-class homogeneity and maximize class separability. This is made possible by promoting pairwise orthogonality between class specific dictionaries and controlling the sparsity structure of the audio clip's decomposition over these dictionaries. The resulting optimization problem is non-convex and solved using a proximal gradient descent method. Experiments are performed on both computational auditory scene (East Anglia and Rouen) and synthetic music chord recognition datasets. Obtained results show that our method is capable to reach state-of-the-art hand-crafted features for both applications.