Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven audio recognition: a supervised dictionary approach
Paper and Code
Dec 29, 2020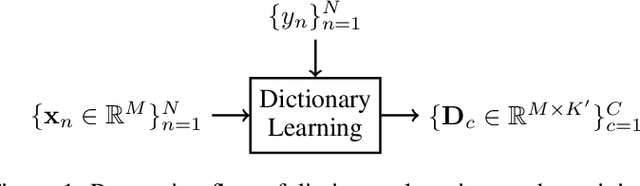
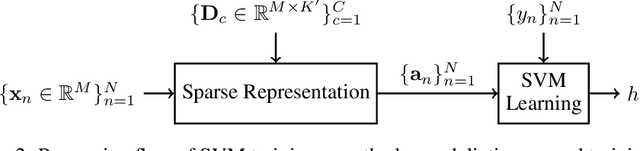
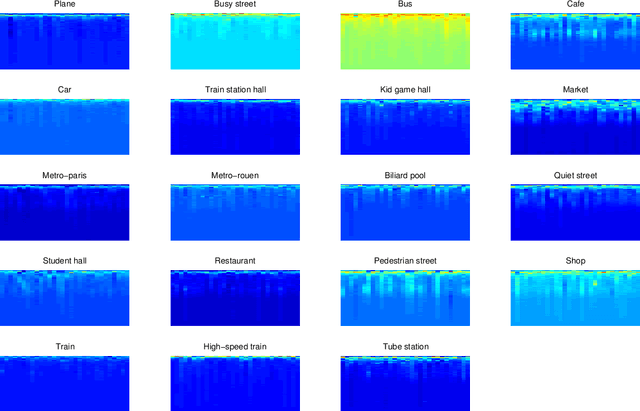
Machine hearing is an emerging area. Motivated by the need of a principled framework across domain applications for machine listening, we propose a generic and data-driven representation learning approach. For this sake, a novel and efficient supervised dictionary learning method is presented. Experiments are performed on both computational auditory scene (East Anglia and Rouen) and synthetic music chord recognition datasets. Obtained results show that our method is capable to reach state-of-the-art hand-crafted features for both applications
* arXiv admin note: substantial text overlap with arXiv:1812.04748
View paper on