 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn efficient supervised dictionary learning method for audio signal recognition
Paper and Code
Dec 12, 2018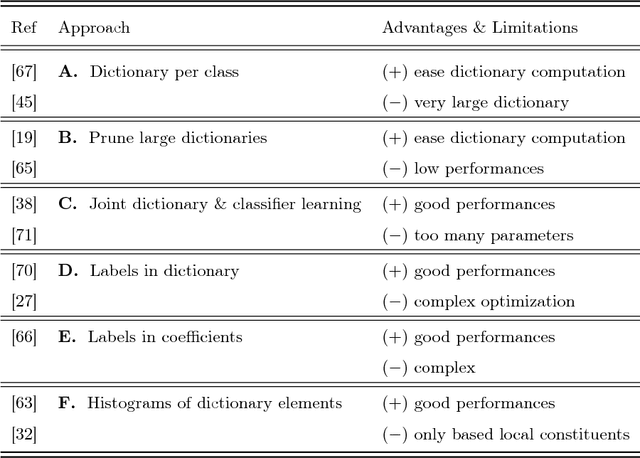
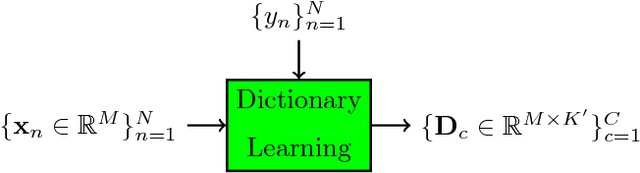
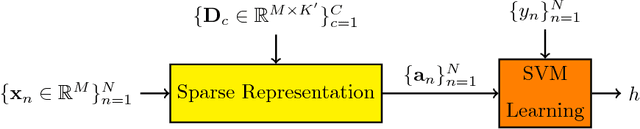
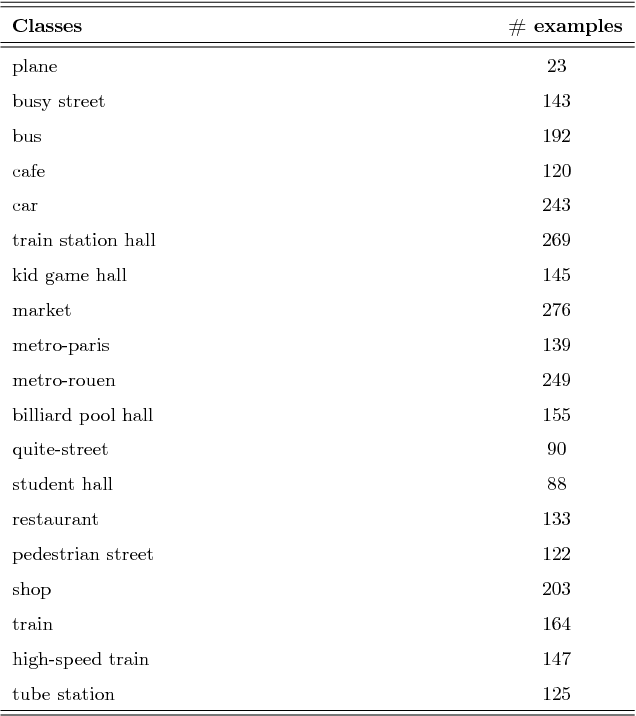
Machine hearing or listening represents an emerging area. Conventional approaches rely on the design of handcrafted features specialized to a specific audio task and that can hardly generalized to other audio fields. For example, Mel-Frequency Cepstral Coefficients (MFCCs) and its variants were successfully applied to computational auditory scene recognition while Chroma vectors are good at music chord recognition. Unfortunately, these predefined features may be of variable discrimination power while extended to other tasks or even within the same task due to different nature of clips. Motivated by this need of a principled framework across domain applications for machine listening, we propose a generic and data-driven representation learning approach. For this sake, a novel and efficient supervised dictionary learning method is presented. The method learns dissimilar dictionaries, one per each class, in order to extract heterogeneous information for classification. In other words, we are seeking to minimize the intra-class homogeneity and maximize class separability. This is made possible by promoting pairwise orthogonality between class specific dictionaries and controlling the sparsity structure of the audio clip's decomposition over these dictionaries. The resulting optimization problem is non-convex and solved using a proximal gradient descent method. Experiments are performed on both computational auditory scene (East Anglia and Rouen) and synthetic music chord recognition datasets. Obtained results show that our method is capable to reach state-of-the-art hand-crafted features for both applications.