 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRDRN: Recursively Defined Residual Network for Image Super-Resolution
Nov 17, 2022Deep convolutional neural networks (CNNs) have obtained remarkable performance in single image super-resolution (SISR). However, very deep networks can suffer from training difficulty and hardly achieve further performance gain. There are two main trends to solve that problem: improving the network architecture for better propagation of features through large number of layers and designing an attention mechanism for selecting most informative features. Recent SISR solutions propose advanced attention and self-attention mechanisms. However, constructing a network to use an attention block in the most efficient way is a challenging problem. To address this issue, we propose a general recursively defined residual block (RDRB) for better feature extraction and propagation through network layers. Based on RDRB we designed recursively defined residual network (RDRN), a novel network architecture which utilizes attention blocks efficiently. Extensive experiments show that the proposed model achieves state-of-the-art results on several popular super-resolution benchmarks and outperforms previous methods by up to 0.43 dB.
Fine-Tuning Transformers: Vocabulary Transfer
Dec 29, 2021

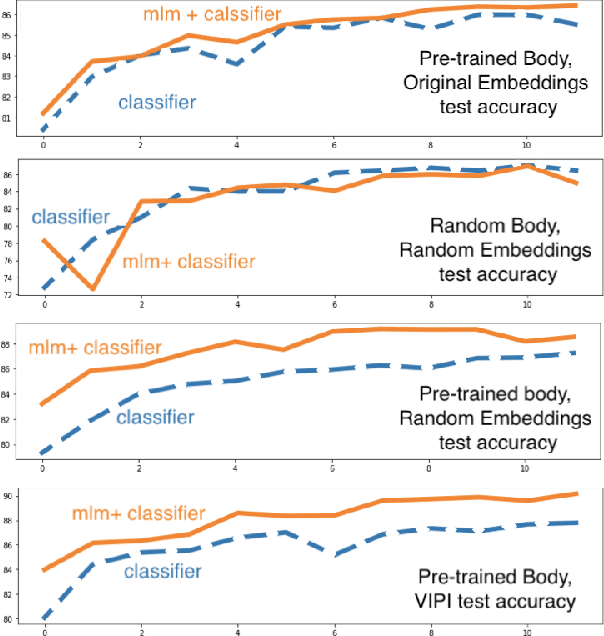
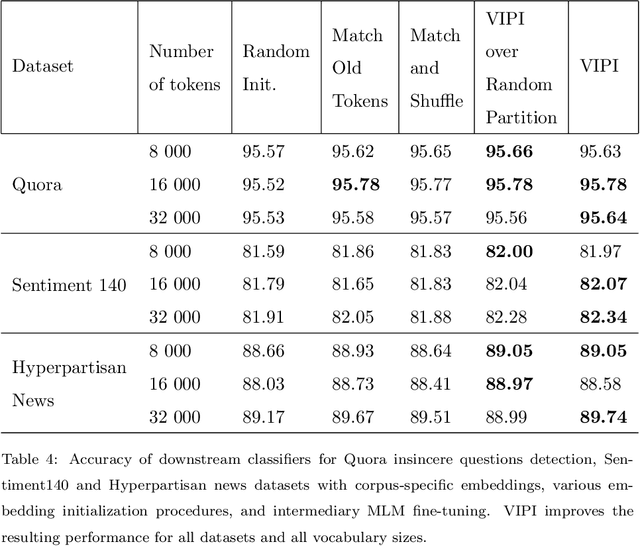
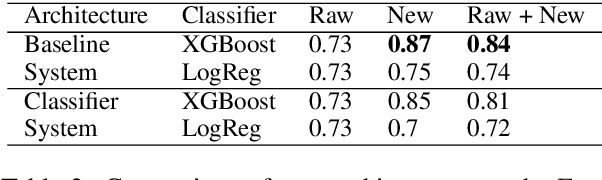
Transformers are responsible for the vast majority of recent advances in natural language processing. The majority of practical natural language processing applications of these models is typically enabled through transfer learning. This paper studies if corpus-specific tokenization used for fine-tuning improves the resulting performance of the model. Through a series of experiments, we demonstrate that such tokenization combined with the initialization and fine-tuning strategy for the vocabulary tokens speeds up the transfer and boosts the performance of the fine-tuned model. We call this aspect of transfer facilitation vocabulary transfer.
StoryDB: Broad Multi-language Narrative Dataset
Sep 29, 2021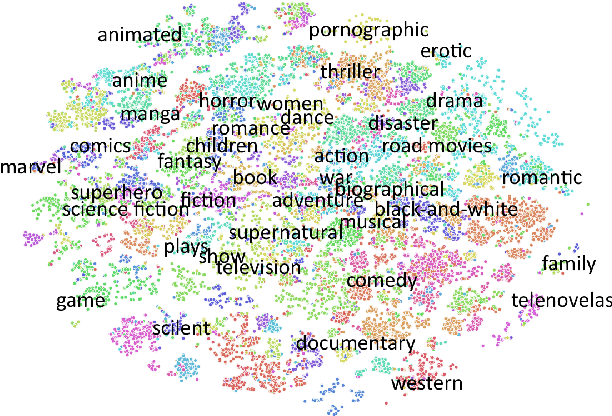
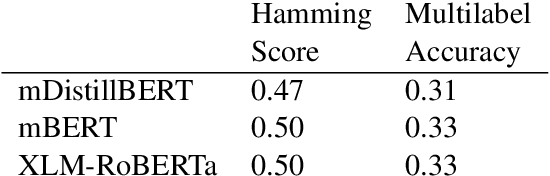
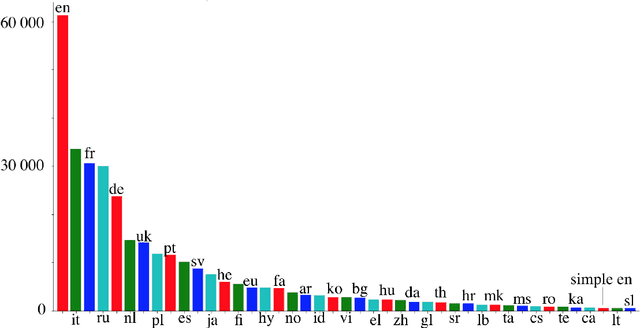
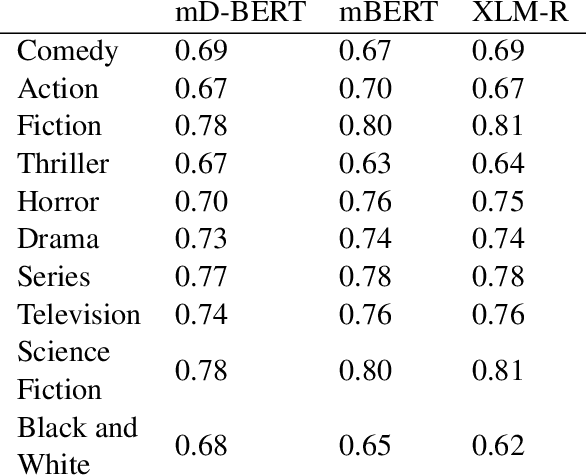
This paper presents StoryDB - a broad multi-language dataset of narratives. StoryDB is a corpus of texts that includes stories in 42 different languages. Every language includes 500+ stories. Some of the languages include more than 20 000 stories. Every story is indexed across languages and labeled with tags such as a genre or a topic. The corpus shows rich topical and language variation and can serve as a resource for the study of the role of narrative in natural language processing across various languages including low resource ones. We also demonstrate how the dataset could be used to benchmark three modern multilanguage models, namely, mDistillBERT, mBERT, and XLM-RoBERTa.
Synonyms and Antonyms: Embedded Conflict
Apr 27, 2020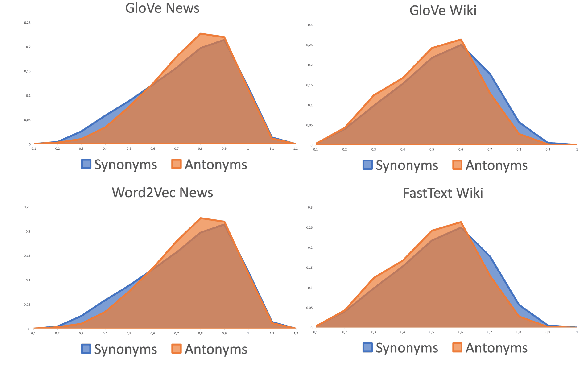
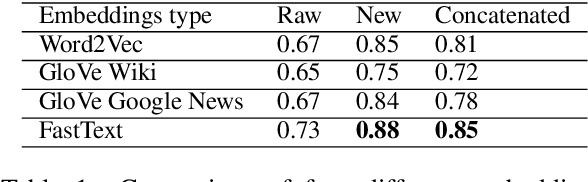
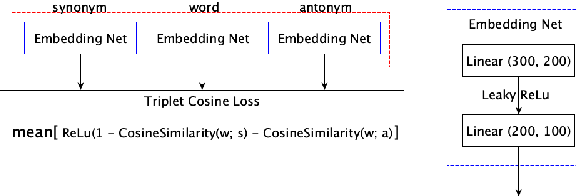
Since modern word embeddings are motivated by a distributional hypothesis and are, therefore, based on local co-occurrences of words, it is only to be expected that synonyms and antonyms can have very similar embeddings. Contrary to this widespread assumption, this paper shows that modern embeddings contain information that distinguishes synonyms and antonyms despite small cosine similarities between corresponding vectors. This information is encoded in the geometry of the embeddings and could be extracted with a manifold learning procedure or {\em contrasting map}. Such a map is trained on a small labeled subset of the data and can produce new empeddings that explicitly highlight specific semantic attributes of the word. The new embeddings produced by the map are shown to improve the performance on downstream tasks.
It Means More if It Sounds Good: Yet Another Hypotheses Concerning the Evolution of Polysemous Words
Mar 12, 2020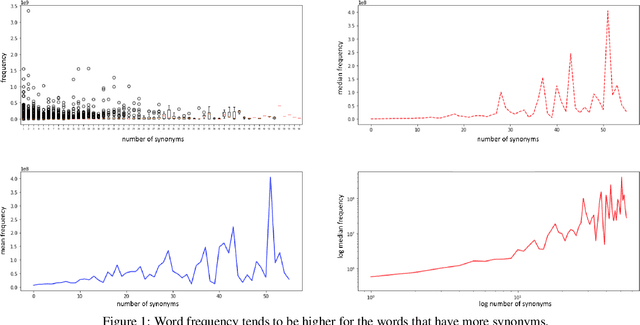
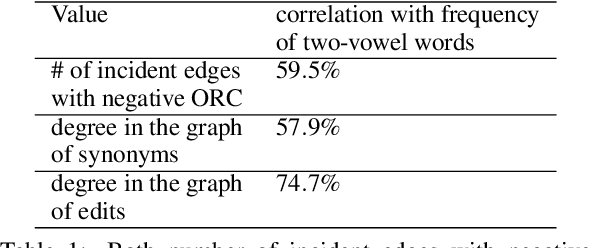
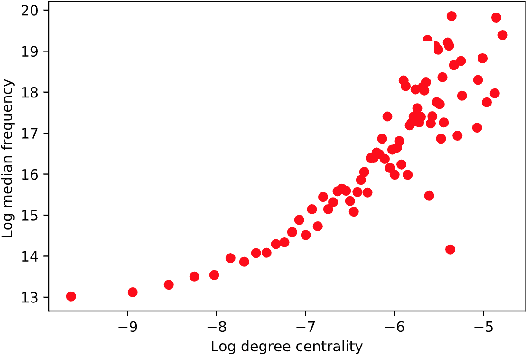
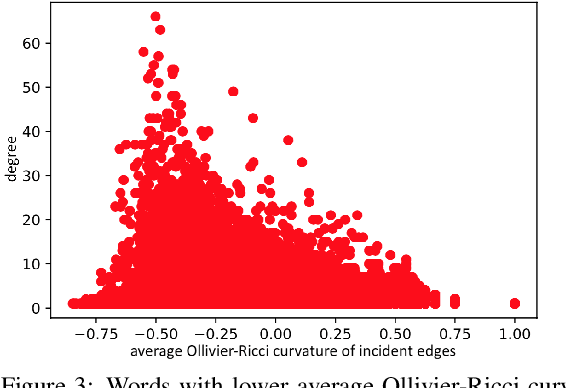
This position paper looks into the formation of language and shows ties between structural properties of the words in the English language and their polysemy. Using Ollivier-Ricci curvature over a large graph of synonyms to estimate polysemy it shows empirically that the words that arguably are easier to pronounce also tend to have multiple meanings.