Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStoryDB: Broad Multi-language Narrative Dataset
Paper and Code
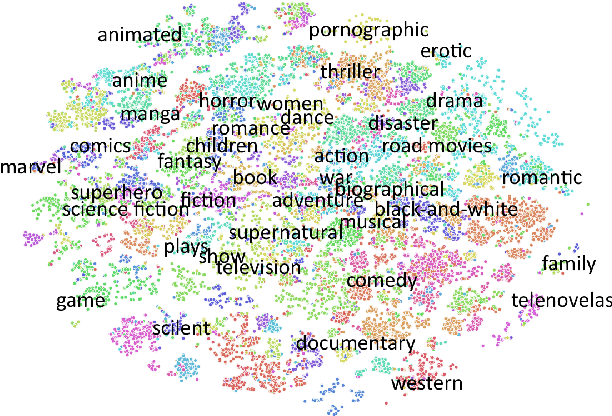
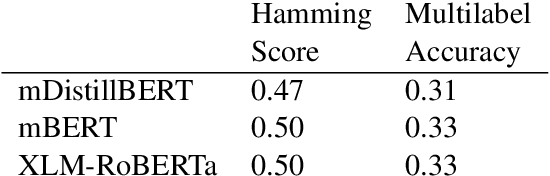
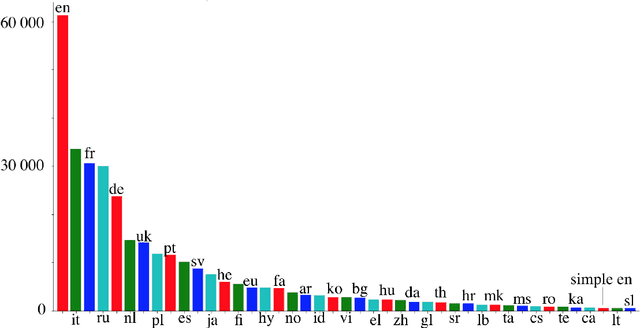
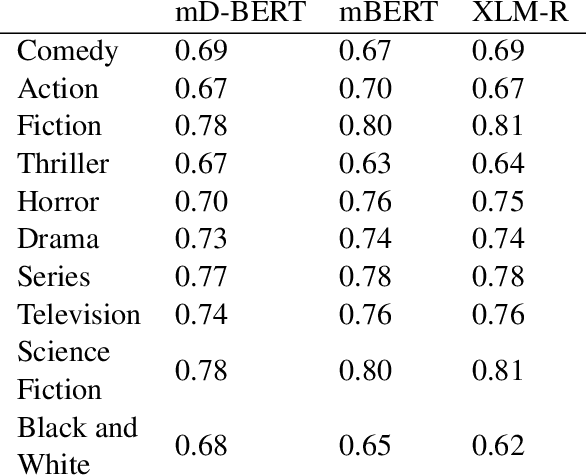
This paper presents StoryDB - a broad multi-language dataset of narratives. StoryDB is a corpus of texts that includes stories in 42 different languages. Every language includes 500+ stories. Some of the languages include more than 20 000 stories. Every story is indexed across languages and labeled with tags such as a genre or a topic. The corpus shows rich topical and language variation and can serve as a resource for the study of the role of narrative in natural language processing across various languages including low resource ones. We also demonstrate how the dataset could be used to benchmark three modern multilanguage models, namely, mDistillBERT, mBERT, and XLM-RoBERTa.
View paper on