 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynonyms and Antonyms: Embedded Conflict
Paper and Code
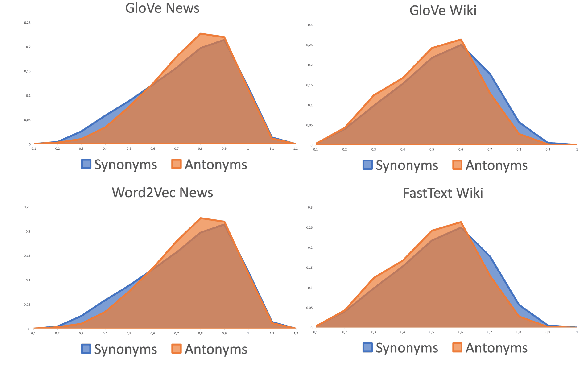
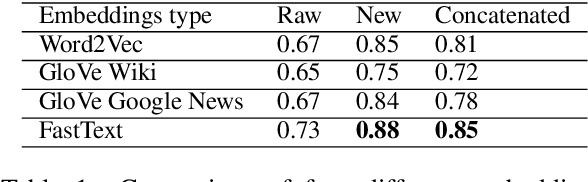
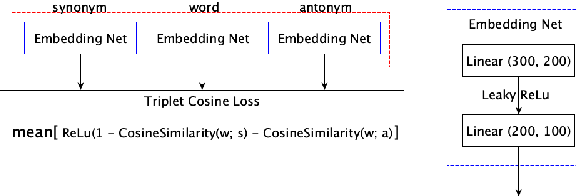
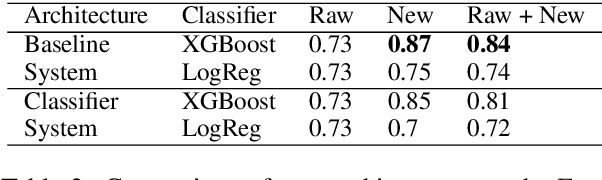
Since modern word embeddings are motivated by a distributional hypothesis and are, therefore, based on local co-occurrences of words, it is only to be expected that synonyms and antonyms can have very similar embeddings. Contrary to this widespread assumption, this paper shows that modern embeddings contain information that distinguishes synonyms and antonyms despite small cosine similarities between corresponding vectors. This information is encoded in the geometry of the embeddings and could be extracted with a manifold learning procedure or {\em contrasting map}. Such a map is trained on a small labeled subset of the data and can produce new empeddings that explicitly highlight specific semantic attributes of the word. The new embeddings produced by the map are shown to improve the performance on downstream tasks.