 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverspecified Mixture Discriminant Analysis: Exponential Convergence, Statistical Guarantees, and Remote Sensing Applications
Oct 30, 2025
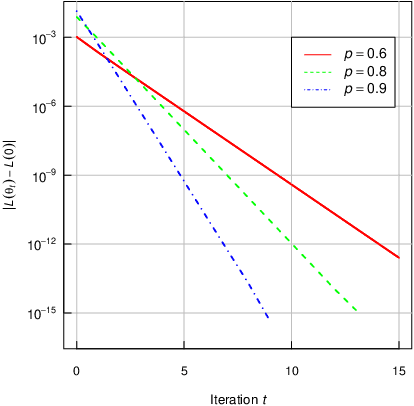
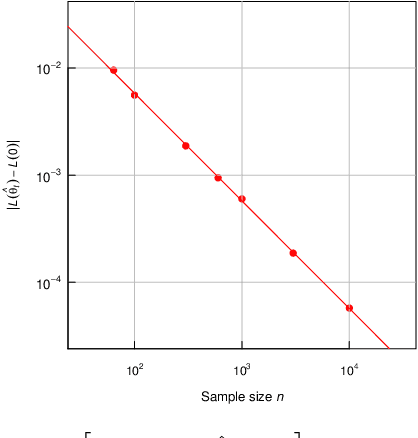
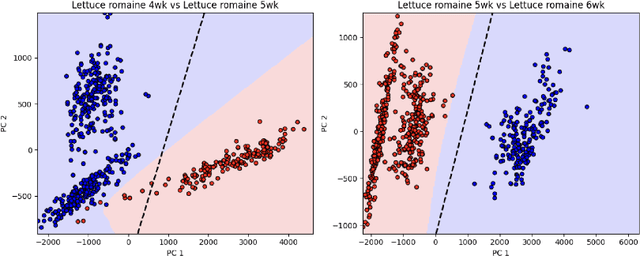
This study explores the classification error of Mixture Discriminant Analysis (MDA) in scenarios where the number of mixture components exceeds those present in the actual data distribution, a condition known as overspecification. We use a two-component Gaussian mixture model within each class to fit data generated from a single Gaussian, analyzing both the algorithmic convergence of the Expectation-Maximization (EM) algorithm and the statistical classification error. We demonstrate that, with suitable initialization, the EM algorithm converges exponentially fast to the Bayes risk at the population level. Further, we extend our results to finite samples, showing that the classification error converges to Bayes risk with a rate $n^{-1/2}$ under mild conditions on the initial parameter estimates and sample size. This work provides a rigorous theoretical framework for understanding the performance of overspecified MDA, which is often used empirically in complex data settings, such as image and text classification. To validate our theory, we conduct experiments on remote sensing datasets.
K-Means Clustering With Incomplete Data with the Use of Mahalanobis Distances
Oct 31, 2024Effectively applying the K-means algorithm to data with missing values remains an important research area due to its impact on applications that rely on K-means clustering. Recent studies have shown that integrating imputation directly into the K-means algorithm yields superior results compared to handling imputation separately. In this work, we extend this approach by developing a unified K-means algorithm that incorporates Mahalanobis distances, instead of the traditional Euclidean distances, which previous research has shown to perform better for clusters with elliptical shapes. We conduct extensive experiments on synthetic datasets containing up to ten elliptical clusters, as well as the IRIS dataset. Using the Adjusted Rand Index (ARI) and Normalized Mutual Information (NMI), we demonstrate that our algorithm consistently outperforms both standalone imputation followed by K-means (using either Mahalanobis or Euclidean distance) and recent K-means algorithms that integrate imputation and clustering for handling incomplete data. These results hold across both the IRIS dataset and randomly generated data with elliptical clusters.
Long-Tail Theory under Gaussian Mixtures
Jul 24, 2023



We suggest a simple Gaussian mixture model for data generation that complies with Feldman's long tail theory (2020). We demonstrate that a linear classifier cannot decrease the generalization error below a certain level in the proposed model, whereas a nonlinear classifier with a memorization capacity can. This confirms that for long-tailed distributions, rare training examples must be considered for optimal generalization to new data. Finally, we show that the performance gap between linear and nonlinear models can be lessened as the tail becomes shorter in the subpopulation frequency distribution, as confirmed by experiments on synthetic and real data.