 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyGen2Vec: Learning Document Embedding via Multi-label Keyword Generation in Question-Answering
Oct 30, 2023



Representing documents into high dimensional embedding space while preserving the structural similarity between document sources has been an ultimate goal for many works on text representation learning. Current embedding models, however, mainly rely on the availability of label supervision to increase the expressiveness of the resulting embeddings. In contrast, unsupervised embeddings are cheap, but they often cannot capture implicit structure in target corpus, particularly for samples that come from different distribution with the pretraining source. Our study aims to loosen up the dependency on label supervision by learning document embeddings via Sequence-to-Sequence (Seq2Seq) text generator. Specifically, we reformulate keyphrase generation task into multi-label keyword generation in community-based Question Answering (cQA). Our empirical results show that KeyGen2Vec in general is superior than multi-label keyword classifier by up to 14.7% based on Purity, Normalized Mutual Information (NMI), and F1-Score metrics. Interestingly, although in general the absolute advantage of learning embeddings through label supervision is highly positive across evaluation datasets, KeyGen2Vec is shown to be competitive with classifier that exploits topic label supervision in Yahoo! cQA with larger number of latent topic labels.
NLG Evaluation Metrics Beyond Correlation Analysis: An Empirical Metric Preference Checklist
May 26, 2023



In this study, we analyze automatic evaluation metrics for Natural Language Generation (NLG), specifically task-agnostic metrics and human-aligned metrics. Task-agnostic metrics, such as Perplexity, BLEU, BERTScore, are cost-effective and highly adaptable to diverse NLG tasks, yet they have a weak correlation with human. Human-aligned metrics (CTC, CtrlEval, UniEval) improves correlation level by incorporating desirable human-like qualities as training objective. However, their effectiveness at discerning system-level performance and quality of system outputs remain unclear. We present metric preference checklist as a framework to assess the effectiveness of automatic metrics in three NLG tasks: Text Summarization, Dialogue Response Generation, and Controlled Generation. Our proposed framework provides access: (i) for verifying whether automatic metrics are faithful to human preference, regardless of their correlation level to human; and (ii) for inspecting the strengths and limitations of NLG systems via pairwise evaluation. We show that automatic metrics provide a better guidance than human on discriminating system-level performance in Text Summarization and Controlled Generation tasks. We also show that multi-aspect human-aligned metric (UniEval) is not necessarily dominant over single-aspect human-aligned metrics (CTC, CtrlEval) and task-agnostic metrics (BLEU, BERTScore), particularly in Controlled Generation tasks.
ProtoInfoMax: Prototypical Networks with Mutual Information Maximization for Out-of-Domain Detection
Sep 10, 2021

The ability to detect Out-of-Domain (OOD) inputs has been a critical requirement in many real-world NLP applications. For example, intent classification in dialogue systems. The reason is that the inclusion of unsupported OOD inputs may lead to catastrophic failure of systems. However, it remains an empirical question whether current methods can tackle such problems reliably in a realistic scenario where zero OOD training data is available. In this study, we propose ProtoInfoMax, a new architecture that extends Prototypical Networks to simultaneously process in-domain and OOD sentences via Mutual Information Maximization (InfoMax) objective. Experimental results show that our proposed method can substantially improve performance up to 20% for OOD detection in low resource settings of text classification. We also show that ProtoInfoMax is less prone to typical overconfidence errors of Neural Networks, leading to more reliable prediction results.
* This manuscript will be available in ACL Anthology section EMNLP2021-Findings papers
BSDAR: Beam Search Decoding with Attention Reward in Neural Keyphrase Generation
Sep 17, 2019
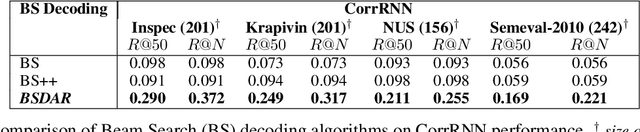
This study mainly investigates two decoding problems in neural keyphrase generation: sequence length bias and beam diversity. We introduce an extension of beam search inference based on word-level and n-gram level attention score to adjust and constrain Seq2Seq prediction at test time. Results show that our proposed solution can overcome the algorithm bias to shorter and nearly identical sequences, resulting in a significant improvement of the decoding performance on generating keyphrases that are present and absent in source text.
Looking Deeper into Deep Learning Model: Attribution-based Explanations of TextCNN
Dec 02, 2018
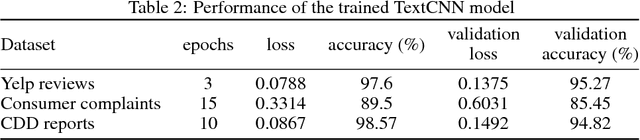
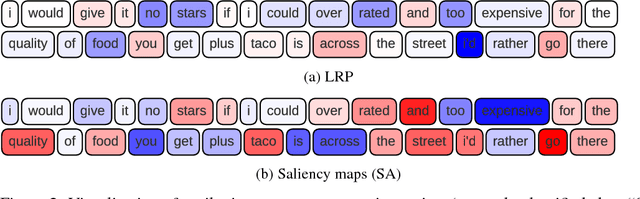
Layer-wise Relevance Propagation (LRP) and saliency maps have been recently used to explain the predictions of Deep Learning models, specifically in the domain of text classification. Given different attribution-based explanations to highlight relevant words for a predicted class label, experiments based on word deleting perturbation is a common evaluation method. This word removal approach, however, disregards any linguistic dependencies that may exist between words or phrases in a sentence, which could semantically guide a classifier to a particular prediction. In this paper, we present a feature-based evaluation framework for comparing the two attribution methods on customer reviews (public data sets) and Customer Due Diligence (CDD) extracted reports (corporate data set). Instead of removing words based on the relevance score, we investigate perturbations based on embedded features removal from intermediate layers of Convolutional Neural Networks. Our experimental study is carried out on embedded-word, embedded-document, and embedded-ngrams explanations. Using the proposed framework, we provide a visualization tool to assist analysts in reasoning toward the model's final prediction.