 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving GANs for Speech Enhancement
Jan 15, 2020

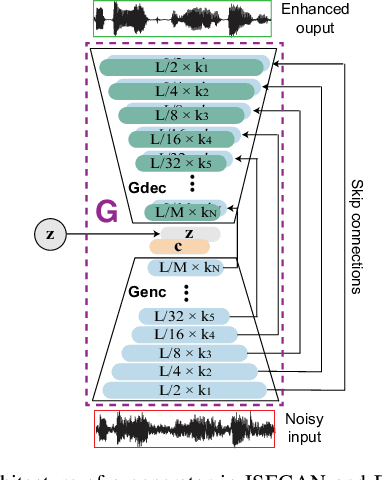

Generative adversarial networks (GAN) have recently been shown to be efficient for speech enhancement. Most, if not all, existing speech enhancement GANs (SEGANs) make use of a single generator to perform one-stage enhancement mapping. In this work, we propose two novel SEGAN frameworks, iterated SEGAN (ISEGAN) and deep SEGAN (DSEGAN). In the two proposed frameworks, the GAN architectures are composed of multiple generators that are chained to accomplish multiple-stage enhancement mapping which gradually refines the noisy input signals in stage-wise fashion. On the one hand, ISEGAN's generators share their parameters to learn an iterative enhancement mapping. On the other hand, DSEGAN's generators share a common architecture but their parameters are independent; as a result, different enhancement mappings are learned at different stages of the network. We empirically demonstrate favorable results obtained by the proposed ISEGAN and DSEGAN frameworks over the vanilla SEGAN. The source code is available at http://github.com/pquochuy/idsegan.