 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Few-Shot Medical Image Segmentation by SAM2: A Training-Free Framework with Augmentative Prompting and Dynamic Matching
Mar 05, 2025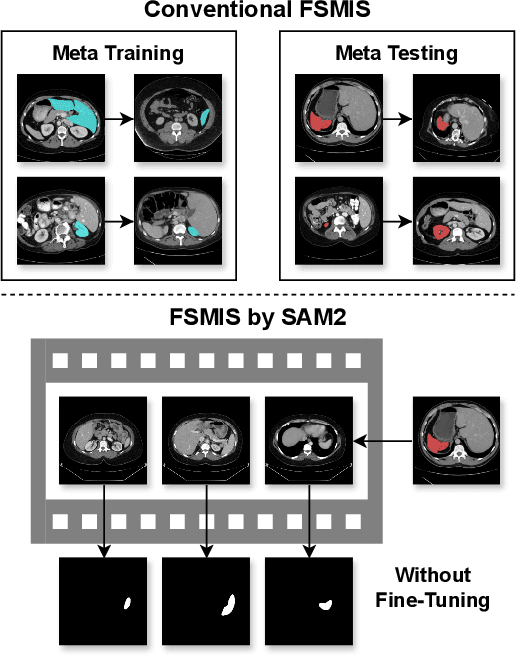
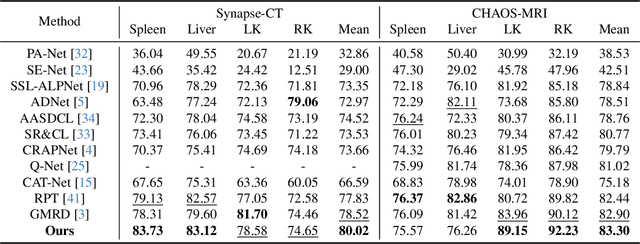
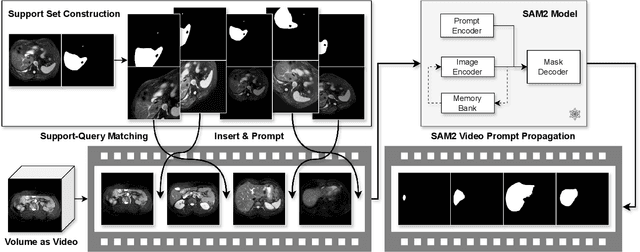
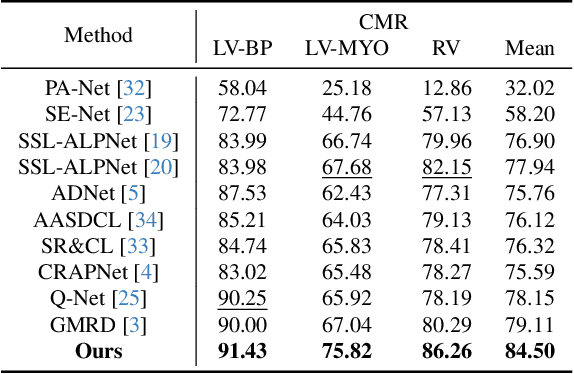
The reliance on large labeled datasets presents a significant challenge in medical image segmentation. Few-shot learning offers a potential solution, but existing methods often still require substantial training data. This paper proposes a novel approach that leverages the Segment Anything Model 2 (SAM2), a vision foundation model with strong video segmentation capabilities. We conceptualize 3D medical image volumes as video sequences, departing from the traditional slice-by-slice paradigm. Our core innovation is a support-query matching strategy: we perform extensive data augmentation on a single labeled support image and, for each frame in the query volume, algorithmically select the most analogous augmented support image. This selected image, along with its corresponding mask, is used as a mask prompt, driving SAM2's video segmentation. This approach entirely avoids model retraining or parameter updates. We demonstrate state-of-the-art performance on benchmark few-shot medical image segmentation datasets, achieving significant improvements in accuracy and annotation efficiency. This plug-and-play method offers a powerful and generalizable solution for 3D medical image segmentation.
LDDMM-Face: Large Deformation Diffeomorphic Metric Learning for Flexible and Consistent Face Alignment
Aug 02, 2021
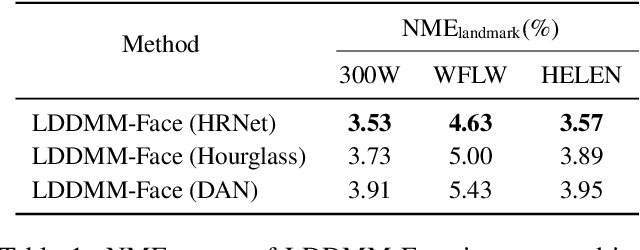
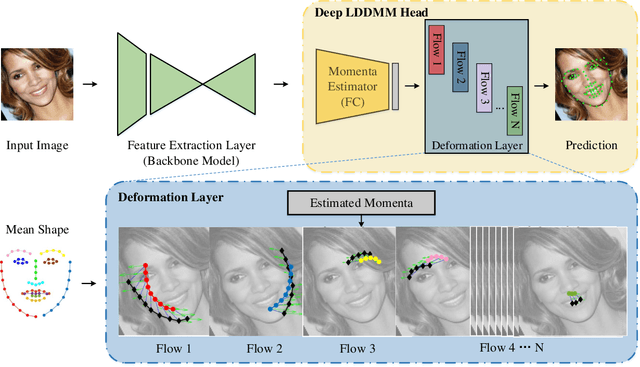
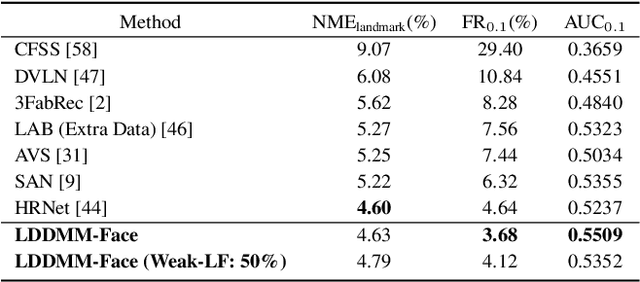
We innovatively propose a flexible and consistent face alignment framework, LDDMM-Face, the key contribution of which is a deformation layer that naturally embeds facial geometry in a diffeomorphic way. Instead of predicting facial landmarks via heatmap or coordinate regression, we formulate this task in a diffeomorphic registration manner and predict momenta that uniquely parameterize the deformation between initial boundary and true boundary, and then perform large deformation diffeomorphic metric mapping (LDDMM) simultaneously for curve and landmark to localize the facial landmarks. Due to the embedding of LDDMM into a deep network, LDDMM-Face can consistently annotate facial landmarks without ambiguity and flexibly handle various annotation schemes, and can even predict dense annotations from sparse ones. Our method can be easily integrated into various face alignment networks. We extensively evaluate LDDMM-Face on four benchmark datasets: 300W, WFLW, HELEN and COFW-68. LDDMM-Face is comparable or superior to state-of-the-art methods for traditional within-dataset and same-annotation settings, but truly distinguishes itself with outstanding performance when dealing with weakly-supervised learning (partial-to-full), challenging cases (e.g., occluded faces), and different training and prediction datasets. In addition, LDDMM-Face shows promising results on the most challenging task of predicting across datasets with different annotation schemes.