 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROMISSING: Pruning Missing Values in Neural Networks
Jun 03, 2022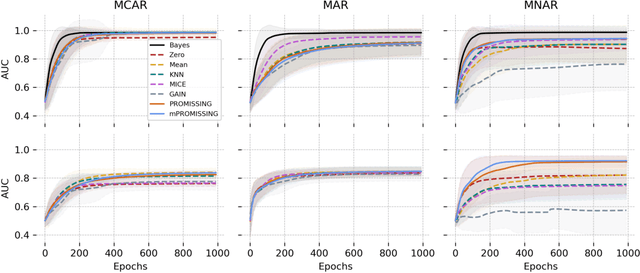
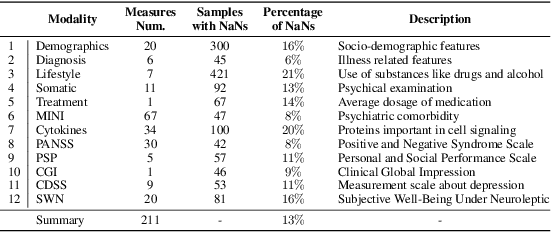
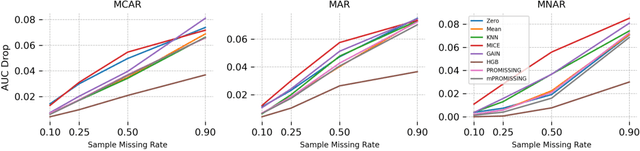
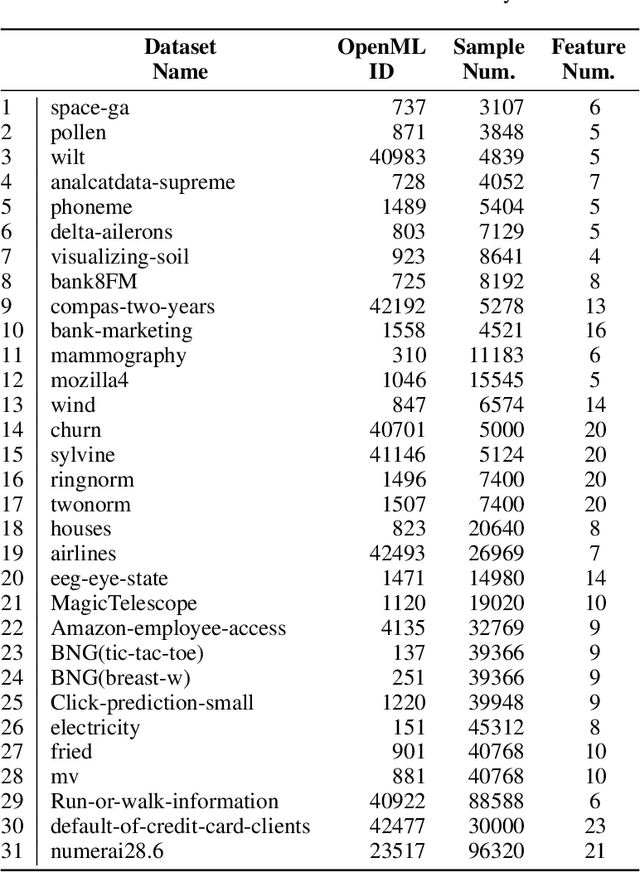
While data are the primary fuel for machine learning models, they often suffer from missing values, especially when collected in real-world scenarios. However, many off-the-shelf machine learning models, including artificial neural network models, are unable to handle these missing values directly. Therefore, extra data preprocessing and curation steps, such as data imputation, are inevitable before learning and prediction processes. In this study, we propose a simple and intuitive yet effective method for pruning missing values (PROMISSING) during learning and inference steps in neural networks. In this method, there is no need to remove or impute the missing values; instead, the missing values are treated as a new source of information (representing what we do not know). Our experiments on simulated data, several classification and regression benchmarks, and a multi-modal clinical dataset show that PROMISSING results in similar prediction performance compared to various imputation techniques. In addition, our experiments show models trained using PROMISSING techniques are becoming less decisive in their predictions when facing incomplete samples with many unknowns. This finding hopefully advances machine learning models from being pure predicting machines to more realistic thinkers that can also say "I do not know" when facing incomplete sources of information.
Active Selection of Classification Features
Feb 26, 2021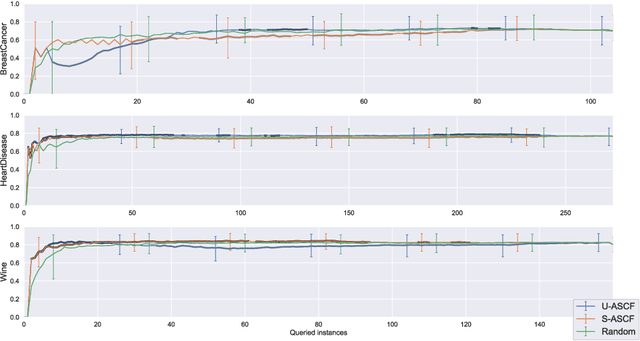
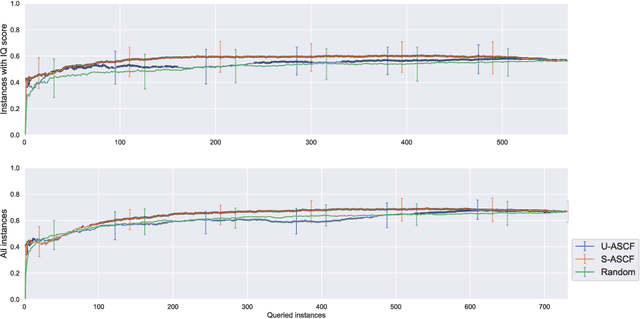
Some data analysis applications comprise datasets, where explanatory variables are expensive or tedious to acquire, but auxiliary data are readily available and might help to construct an insightful training set. An example is neuroimaging research on mental disorders, specifically learning a diagnosis/prognosis model based on variables derived from expensive Magnetic Resonance Imaging (MRI) scans, which often requires large sample sizes. Auxiliary data, such as demographics, might help in selecting a smaller sample that comprises the individuals with the most informative MRI scans. In active learning literature, this problem has not yet been studied, despite promising results in related problem settings that concern the selection of instances or instance-feature pairs. Therefore, we formulate this complementary problem of Active Selection of Classification Features (ASCF): Given a primary task, which requires to learn a model f: x-> y to explain/predict the relationship between an expensive-to-acquire set of variables x and a class label y. Then, the ASCF-task is to use a set of readily available selection variables z to select these instances, that will improve the primary task's performance most when acquiring their expensive features z and including them to the primary training set. We propose two utility-based approaches for this problem, and evaluate their performance on three public real-world benchmark datasets. In addition, we illustrate the use of these approaches to efficiently acquire MRI scans in the context of neuroimaging research on mental disorders, based on a simulated study design with real MRI data.