 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Sketching for Kronecker Product Regression and Low Rank Approximation
Sep 29, 2019
We study the Kronecker product regression problem, in which the design matrix is a Kronecker product of two or more matrices. Given $A_i \in \mathbb{R}^{n_i \times d_i}$ for $i=1,2,\dots,q$ where $n_i \gg d_i$ for each $i$, and $b \in \mathbb{R}^{n_1 n_2 \cdots n_q}$, let $\mathcal{A} = A_1 \otimes A_2 \otimes \cdots \otimes A_q$. Then for $p \in [1,2]$, the goal is to find $x \in \mathbb{R}^{d_1 \cdots d_q}$ that approximately minimizes $\|\mathcal{A}x - b\|_p$. Recently, Diao, Song, Sun, and Woodruff (AISTATS, 2018) gave an algorithm which is faster than forming the Kronecker product $\mathcal{A}$ Specifically, for $p=2$ their running time is $O(\sum_{i=1}^q \text{nnz}(A_i) + \text{nnz}(b))$, where nnz$(A_i)$ is the number of non-zero entries in $A_i$. Note that nnz$(b)$ can be as large as $n_1 \cdots n_q$. For $p=1,$ $q=2$ and $n_1 = n_2$, they achieve a worse bound of $O(n_1^{3/2} \text{poly}(d_1d_2) + \text{nnz}(b))$. In this work, we provide significantly faster algorithms. For $p=2$, our running time is $O(\sum_{i=1}^q \text{nnz}(A_i) )$, which has no dependence on nnz$(b)$. For $p<2$, our running time is $O(\sum_{i=1}^q \text{nnz}(A_i) + \text{nnz}(b))$, which matches the prior best running time for $p=2$. We also consider the related all-pairs regression problem, where given $A \in \mathbb{R}^{n \times d}, b \in \mathbb{R}^n$, we want to solve $\min_{x} \|\bar{A}x - \bar{b}\|_p$, where $\bar{A} \in \mathbb{R}^{n^2 \times d}, \bar{b} \in \mathbb{R}^{n^2}$ consist of all pairwise differences of the rows of $A,b$. We give an $O(\text{nnz}(A))$ time algorithm for $p \in[1,2]$, improving the $\Omega(n^2)$ time needed to form $\bar{A}$. Finally, we initiate the study of Kronecker product low rank and low $t$-rank approximation. For input $\mathcal{A}$ as above, we give $O(\sum_{i=1}^q \text{nnz}(A_i))$ time algorithms, which is much faster than computing $\mathcal{A}$.
Total Least Squares Regression in Input Sparsity Time
Sep 27, 2019
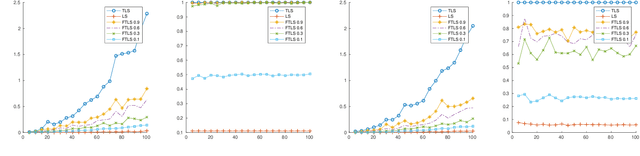
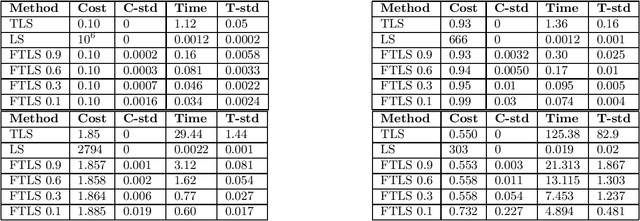
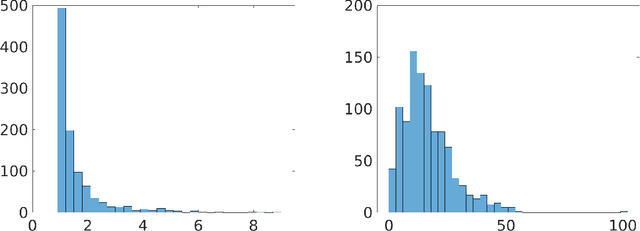
In the total least squares problem, one is given an $m \times n$ matrix $A$, and an $m \times d$ matrix $B$, and one seeks to "correct" both $A$ and $B$, obtaining matrices $\hat{A}$ and $\hat{B}$, so that there exists an $X$ satisfying the equation $\hat{A}X = \hat{B}$. Typically the problem is overconstrained, meaning that $m \gg \max(n,d)$. The cost of the solution $\hat{A}, \hat{B}$ is given by $\|A-\hat{A}\|_F^2 + \|B - \hat{B}\|_F^2$. We give an algorithm for finding a solution $X$ to the linear system $\hat{A}X=\hat{B}$ for which the cost $\|A-\hat{A}\|_F^2 + \|B-\hat{B}\|_F^2$ is at most a multiplicative $(1+\epsilon)$ factor times the optimal cost, up to an additive error $\eta$ that may be an arbitrarily small function of $n$. Importantly, our running time is $\tilde{O}( \mathrm{nnz}(A) + \mathrm{nnz}(B) ) + \mathrm{poly}(n/\epsilon) \cdot d$, where for a matrix $C$, $\mathrm{nnz}(C)$ denotes its number of non-zero entries. Importantly, our running time does not directly depend on the large parameter $m$. As total least squares regression is known to be solvable via low rank approximation, a natural approach is to invoke fast algorithms for approximate low rank approximation, obtaining matrices $\hat{A}$ and $\hat{B}$ from this low rank approximation, and then solving for $X$ so that $\hat{A}X = \hat{B}$. However, existing algorithms do not apply since in total least squares the rank of the low rank approximation needs to be $n$, and so the running time of known methods would be at least $mn^2$. In contrast, we are able to achieve a much faster running time for finding $X$ by never explicitly forming the equation $\hat{A} X = \hat{B}$, but instead solving for an $X$ which is a solution to an implicit such equation. Finally, we generalize our algorithm to the total least squares problem with regularization.
Sketching for Kronecker Product Regression and P-splines
Dec 27, 2017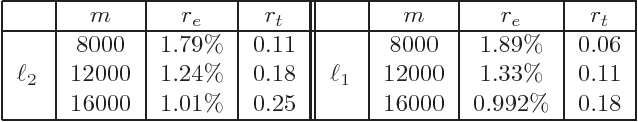
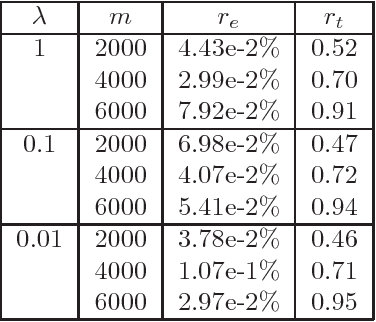
TensorSketch is an oblivious linear sketch introduced in Pagh'13 and later used in Pham, Pagh'13 in the context of SVMs for polynomial kernels. It was shown in Avron, Nguyen, Woodruff'14 that TensorSketch provides a subspace embedding, and therefore can be used for canonical correlation analysis, low rank approximation, and principal component regression for the polynomial kernel. We take TensorSketch outside of the context of polynomials kernels, and show its utility in applications in which the underlying design matrix is a Kronecker product of smaller matrices. This allows us to solve Kronecker product regression and non-negative Kronecker product regression, as well as regularized spline regression. Our main technical result is then in extending TensorSketch to other norms. That is, TensorSketch only provides input sparsity time for Kronecker product regression with respect to the $2$-norm. We show how to solve Kronecker product regression with respect to the $1$-norm in time sublinear in the time required for computing the Kronecker product, as well as for more general $p$-norms.