 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADAR: Retrieval-Augmented Detector with Adversarial Refinement for Robust Fake News Detection
Jan 07, 2026To efficiently combat the spread of LLM-generated misinformation, we present RADAR, a retrieval-augmented detector with adversarial refinement for robust fake news detection. Our approach employs a generator that rewrites real articles with factual perturbations, paired with a lightweight detector that verifies claims using dense passage retrieval. To enable effective co-evolution, we introduce verbal adversarial feedback (VAF). Rather than relying on scalar rewards, VAF issues structured natural-language critiques; these guide the generator toward more sophisticated evasion attempts, compelling the detector to adapt and improve. On a fake news detection benchmark, RADAR achieves 86.98% ROC-AUC, significantly outperforming general-purpose LLMs with retrieval. Ablation studies confirm that detector-side retrieval yields the largest gains, while VAF and few-shot demonstrations provide critical signals for robust training.
Dixit: Interactive Visual Storytelling via Term Manipulation
Mar 11, 2019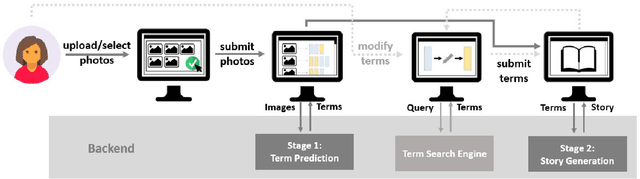

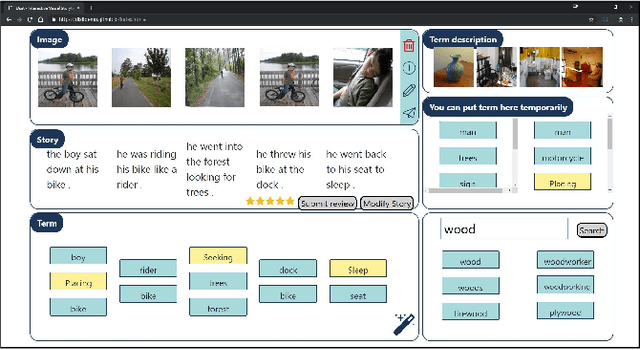
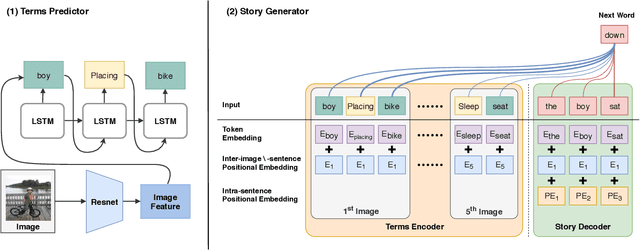
In this paper, we introduce Dixit, an interactive visual storytelling system that the user interacts with iteratively to compose a short story for a photo sequence. The user initiates the process by uploading a sequence of photos. Dixit first extracts text terms from each photo which describe the objects (e.g., boy, bike) or actions (e.g., sleep) in the photo, and then allows the user to add new terms or remove existing terms. Dixit then generates a short story based on these terms. Behind the scenes, Dixit uses an LSTM-based model trained on image caption data and FrameNet to distill terms from each image and utilizes a transformer decoder to compose a context-coherent story. Users change images or terms iteratively with Dixit to create the most ideal story. Dixit also allows users to manually edit and rate stories. The proposed procedure opens up possibilities for interpretable and controllable visual storytelling, allowing users to understand the story formation rationale and to intervene in the generation process.