 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Elastic Demand for Forecasting
Sep 09, 2018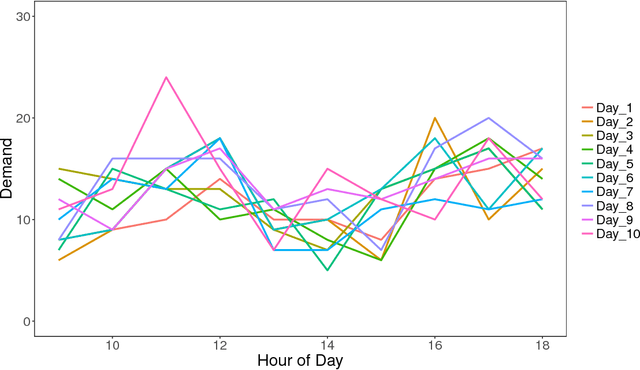


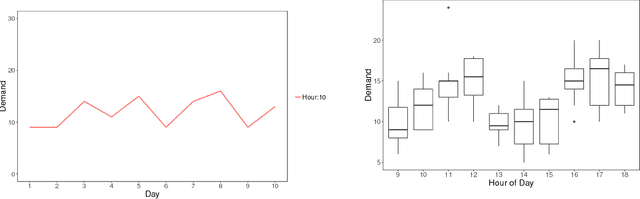
Demand variance can result in a mismatch between planned supply and actual demand. Demand shaping strategies such as pricing can be used to shift elastic demand to reduce the imbalance. In this work, we propose to consider elastic demand in the forecasting phase. We present a method to reallocate the historical elastic demand to reduce variance, thus making forecasting and supply planning more effective.
Interpreting Tree Ensembles with inTrees
Aug 23, 2014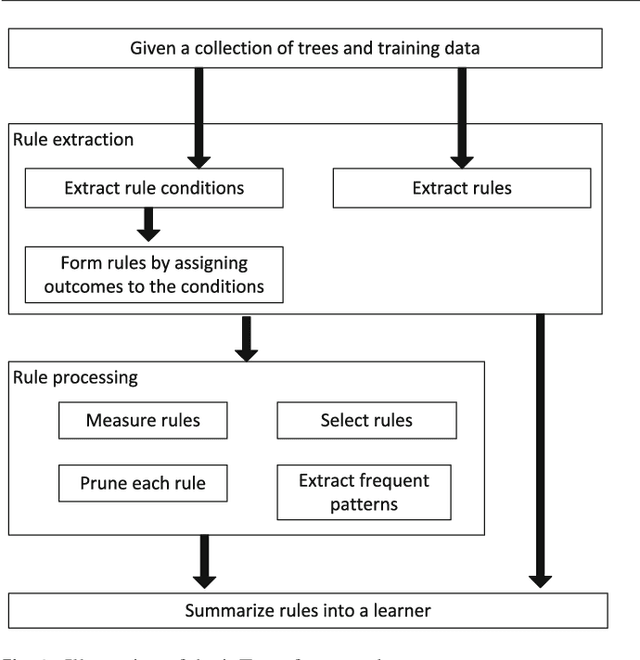
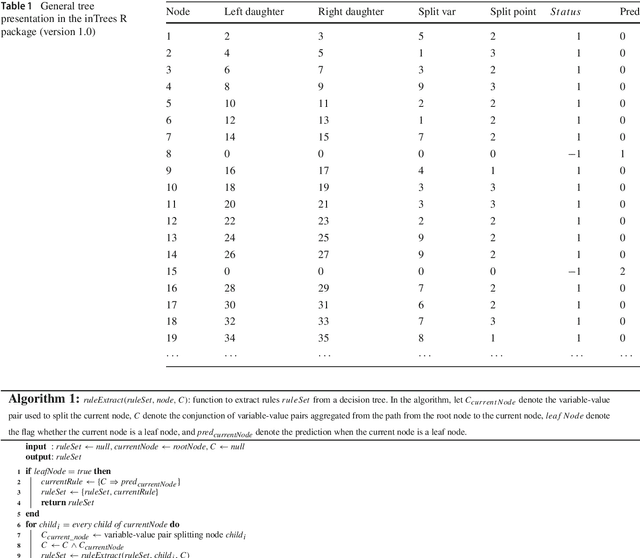
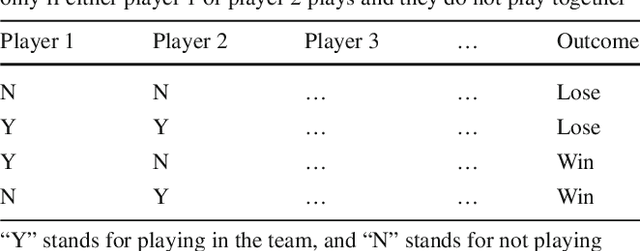
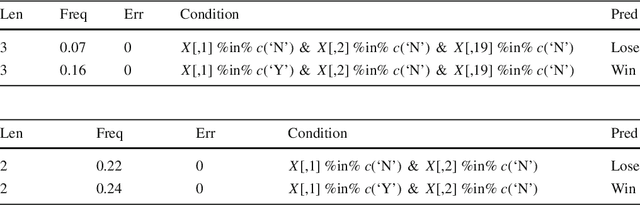
Tree ensembles such as random forests and boosted trees are accurate but difficult to understand, debug and deploy. In this work, we provide the inTrees (interpretable trees) framework that extracts, measures, prunes and selects rules from a tree ensemble, and calculates frequent variable interactions. An rule-based learner, referred to as the simplified tree ensemble learner (STEL), can also be formed and used for future prediction. The inTrees framework can applied to both classification and regression problems, and is applicable to many types of tree ensembles, e.g., random forests, regularized random forests, and boosted trees. We implemented the inTrees algorithms in the "inTrees" R package.
Guided Random Forest in the RRF Package
Nov 18, 2013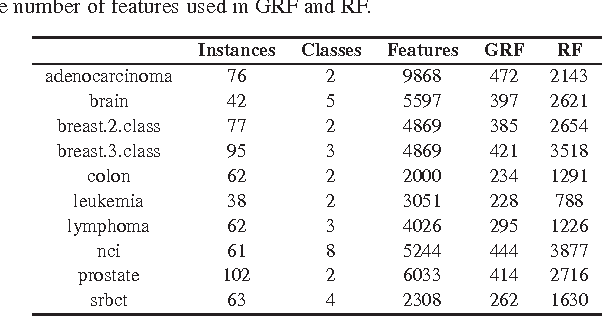
Random Forest (RF) is a powerful supervised learner and has been popularly used in many applications such as bioinformatics. In this work we propose the guided random forest (GRF) for feature selection. Similar to a feature selection method called guided regularized random forest (GRRF), GRF is built using the importance scores from an ordinary RF. However, the trees in GRRF are built sequentially, are highly correlated and do not allow for parallel computing, while the trees in GRF are built independently and can be implemented in parallel. Experiments on 10 high-dimensional gene data sets show that, with a fixed parameter value (without tuning the parameter), RF applied to features selected by GRF outperforms RF applied to all features on 9 data sets and 7 of them have significant differences at the 0.05 level. Therefore, both accuracy and interpretability are significantly improved. GRF selects more features than GRRF, however, leads to better classification accuracy. Note in this work the guided random forest is guided by the importance scores from an ordinary random forest, however, it can also be guided by other methods such as human insights (by specifying $\lambda_i$). GRF can be used in "RRF" v1.4 (and later versions), a package that also includes the regularized random forest methods.
Gene selection with guided regularized random forest
Jun 20, 2013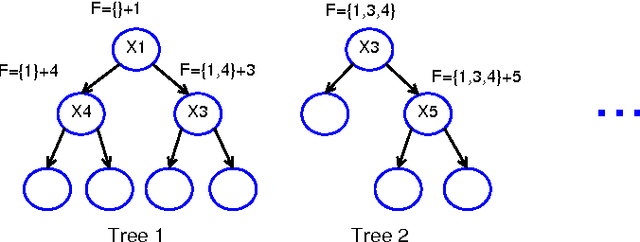

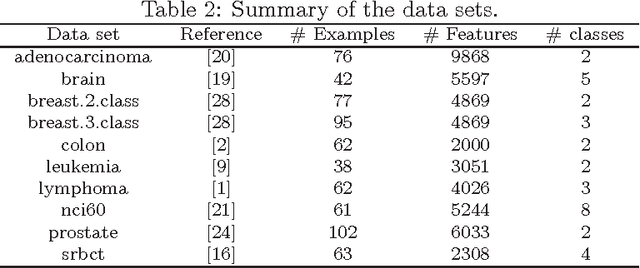
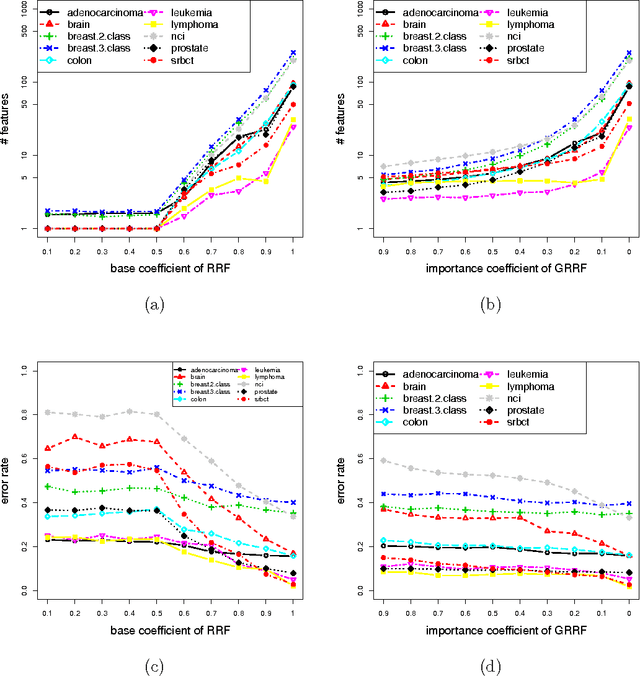
The regularized random forest (RRF) was recently proposed for feature selection by building only one ensemble. In RRF the features are evaluated on a part of the training data at each tree node. We derive an upper bound for the number of distinct Gini information gain values in a node, and show that many features can share the same information gain at a node with a small number of instances and a large number of features. Therefore, in a node with a small number of instances, RRF is likely to select a feature not strongly relevant. Here an enhanced RRF, referred to as the guided RRF (GRRF), is proposed. In GRRF, the importance scores from an ordinary random forest (RF) are used to guide the feature selection process in RRF. Experiments on 10 gene data sets show that the accuracy performance of GRRF is, in general, more robust than RRF when their parameters change. GRRF is computationally efficient, can select compact feature subsets, and has competitive accuracy performance, compared to RRF, varSelRF and LASSO logistic regression (with evaluations from an RF classifier). Also, RF applied to the features selected by RRF with the minimal regularization outperforms RF applied to all the features for most of the data sets considered here. Therefore, if accuracy is considered more important than the size of the feature subset, RRF with the minimal regularization may be considered. We use the accuracy performance of RF, a strong classifier, to evaluate feature selection methods, and illustrate that weak classifiers are less capable of capturing the information contained in a feature subset. Both RRF and GRRF were implemented in the "RRF" R package available at CRAN, the official R package archive.
A Time Series Forest for Classification and Feature Extraction
Feb 18, 2013
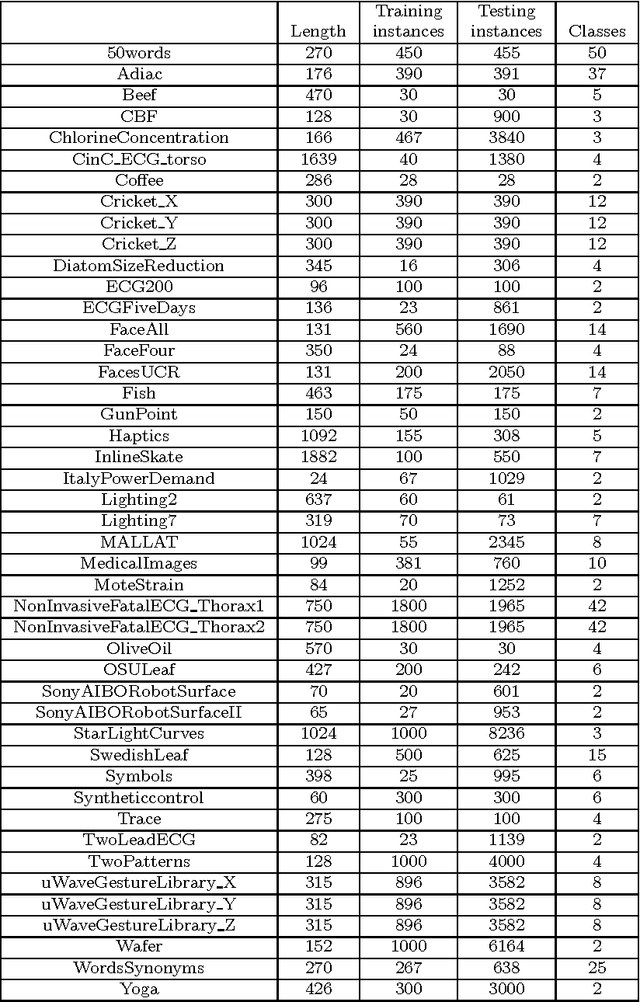
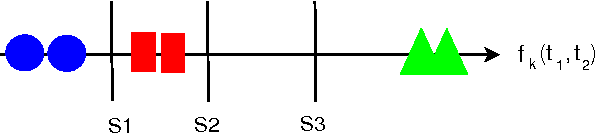
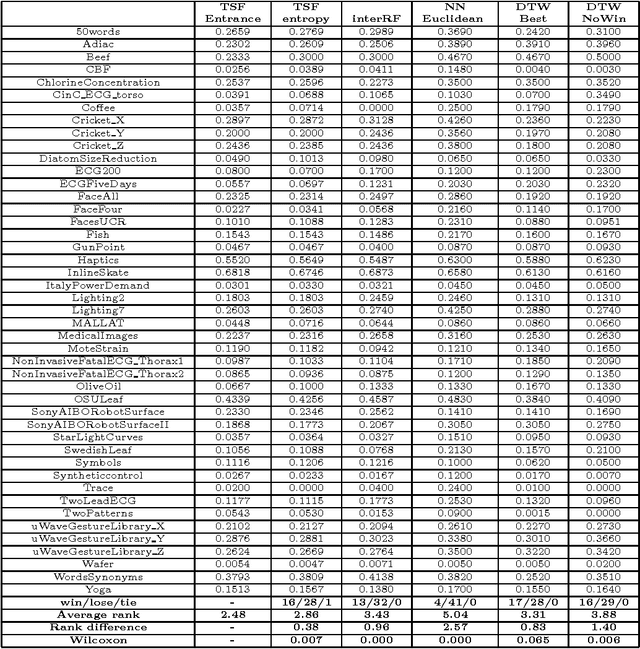
We propose a tree ensemble method, referred to as time series forest (TSF), for time series classification. TSF employs a combination of the entropy gain and a distance measure, referred to as the Entrance (entropy and distance) gain, for evaluating the splits. Experimental studies show that the Entrance gain criterion improves the accuracy of TSF. TSF randomly samples features at each tree node and has a computational complexity linear in the length of a time series and can be built using parallel computing techniques such as multi-core computing used here. The temporal importance curve is also proposed to capture the important temporal characteristics useful for classification. Experimental studies show that TSF using simple features such as mean, deviation and slope outperforms strong competitors such as one-nearest-neighbor classifiers with dynamic time warping, is computationally efficient, and can provide insights into the temporal characteristics.
Feature Selection via Regularized Trees
Mar 21, 2012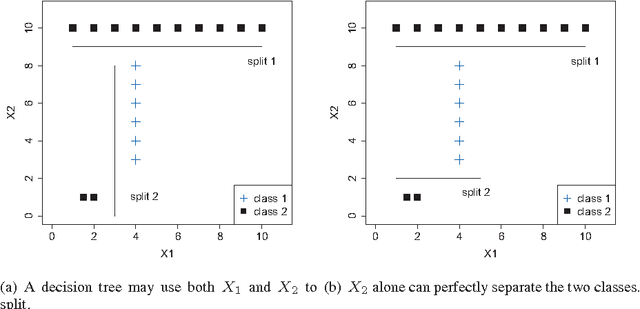
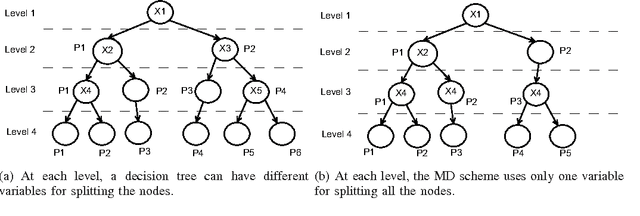
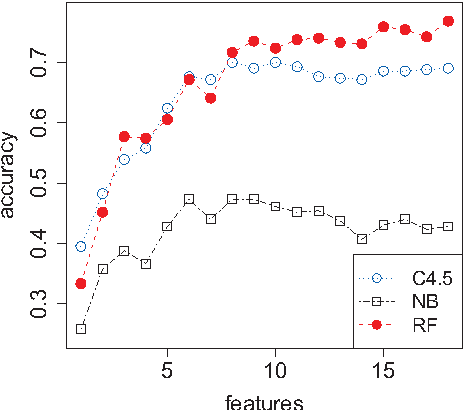
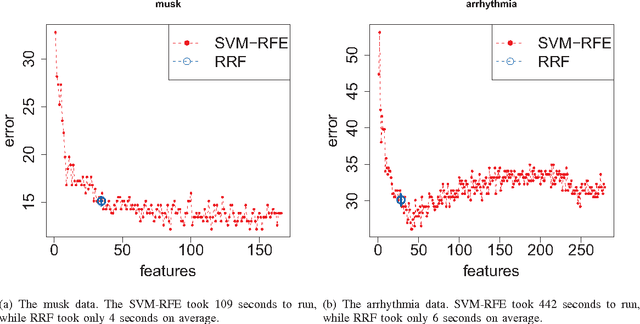
We propose a tree regularization framework, which enables many tree models to perform feature selection efficiently. The key idea of the regularization framework is to penalize selecting a new feature for splitting when its gain (e.g. information gain) is similar to the features used in previous splits. The regularization framework is applied on random forest and boosted trees here, and can be easily applied to other tree models. Experimental studies show that the regularized trees can select high-quality feature subsets with regard to both strong and weak classifiers. Because tree models can naturally deal with categorical and numerical variables, missing values, different scales between variables, interactions and nonlinearities etc., the tree regularization framework provides an effective and efficient feature selection solution for many practical problems.