 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based Reinforcement Learning for Combinatorial Optimization: Application to Job Shop Scheduling Problem
Jan 29, 2024



Job shop scheduling problems are one of the most important and challenging combinatorial optimization problems that have been tackled mainly by exact or approximate solution approaches. However, finding an exact solution can be infeasible for real-world problems, and even with an approximate solution approach, it can require a prohibitive amount of time to find a near-optimal solution, and the found solutions are not applicable to new problems in general. To address these challenges, we propose an attention-based reinforcement learning method for the class of job shop scheduling problems by integrating policy gradient reinforcement learning with a modified transformer architecture. An important result is that our trained learners in the proposed method can be reused to solve large-scale problems not used in training and demonstrate that our approach outperforms the results of recent studies and widely adopted heuristic rules.
Dynamic Exploration-Exploitation Trade-Off in Active Learning Regression with Bayesian Hierarchical Modeling
Apr 16, 2023Active learning provides a framework to adaptively sample the most informative experiments towards learning an unknown black-box function. Various approaches of active learning have been proposed in the literature, however, they either focus on exploration or exploitation in the design space. Methods that do consider exploration-exploitation simultaneously employ fixed or ad-hoc measures to control the trade-off that may not be optimal. In this paper, we develop a Bayesian hierarchical approach to dynamically balance the exploration-exploitation trade-off as more data points are queried. We subsequently formulate an approximate Bayesian computation approach based on the linear dependence of data samples in the feature space to sample from the posterior distribution of the trade-off parameter obtained from the Bayesian hierarchical model. Simulated and real-world examples show the proposed approach achieves at least 6% and 11% average improvement when compared to pure exploration and exploitation strategies respectively. More importantly, we note that by optimally balancing the trade-off between exploration and exploitation, our approach performs better or at least as well as either pure exploration or pure exploitation.
Gene selection with guided regularized random forest
Jun 20, 2013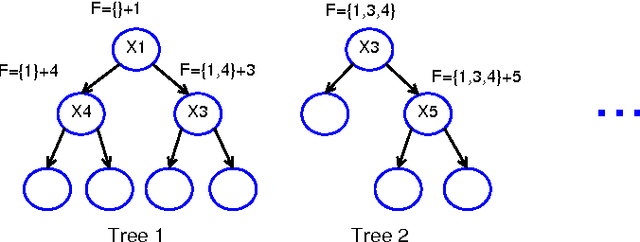

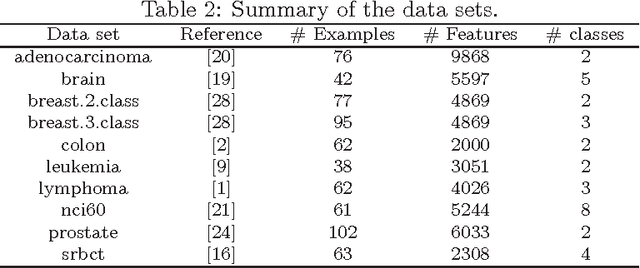
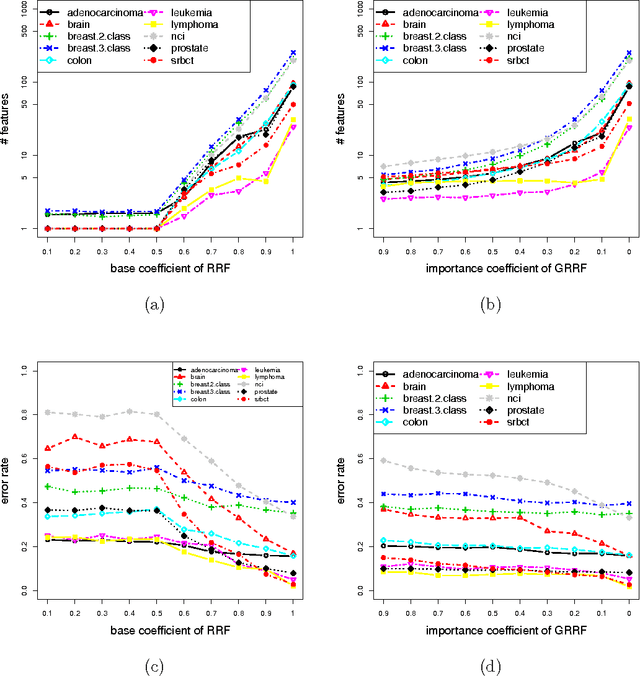
The regularized random forest (RRF) was recently proposed for feature selection by building only one ensemble. In RRF the features are evaluated on a part of the training data at each tree node. We derive an upper bound for the number of distinct Gini information gain values in a node, and show that many features can share the same information gain at a node with a small number of instances and a large number of features. Therefore, in a node with a small number of instances, RRF is likely to select a feature not strongly relevant. Here an enhanced RRF, referred to as the guided RRF (GRRF), is proposed. In GRRF, the importance scores from an ordinary random forest (RF) are used to guide the feature selection process in RRF. Experiments on 10 gene data sets show that the accuracy performance of GRRF is, in general, more robust than RRF when their parameters change. GRRF is computationally efficient, can select compact feature subsets, and has competitive accuracy performance, compared to RRF, varSelRF and LASSO logistic regression (with evaluations from an RF classifier). Also, RF applied to the features selected by RRF with the minimal regularization outperforms RF applied to all the features for most of the data sets considered here. Therefore, if accuracy is considered more important than the size of the feature subset, RRF with the minimal regularization may be considered. We use the accuracy performance of RF, a strong classifier, to evaluate feature selection methods, and illustrate that weak classifiers are less capable of capturing the information contained in a feature subset. Both RRF and GRRF were implemented in the "RRF" R package available at CRAN, the official R package archive.
A Time Series Forest for Classification and Feature Extraction
Feb 18, 2013
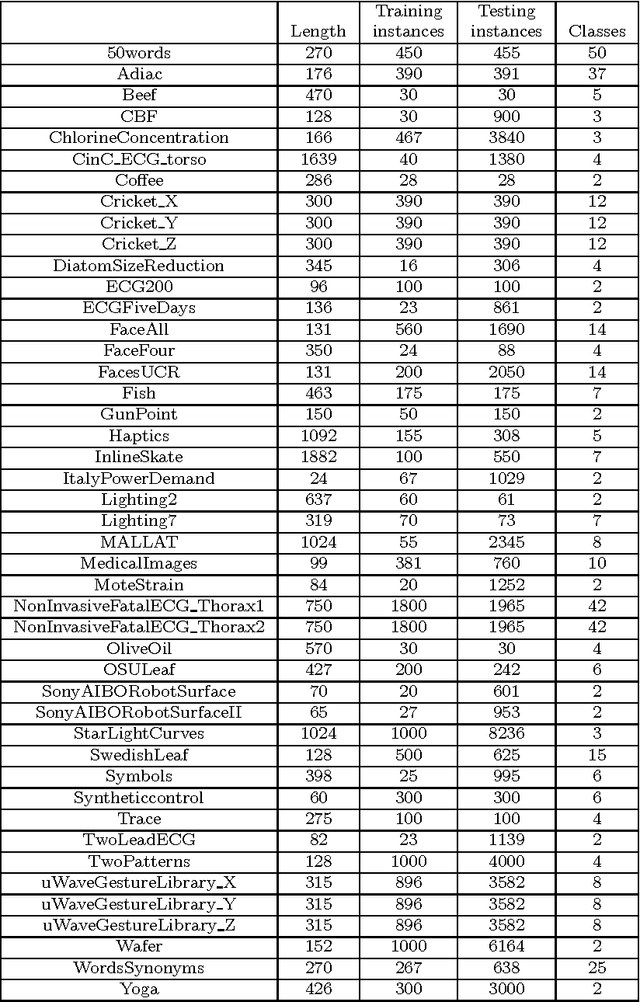
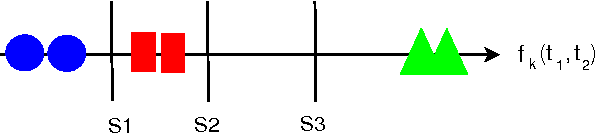
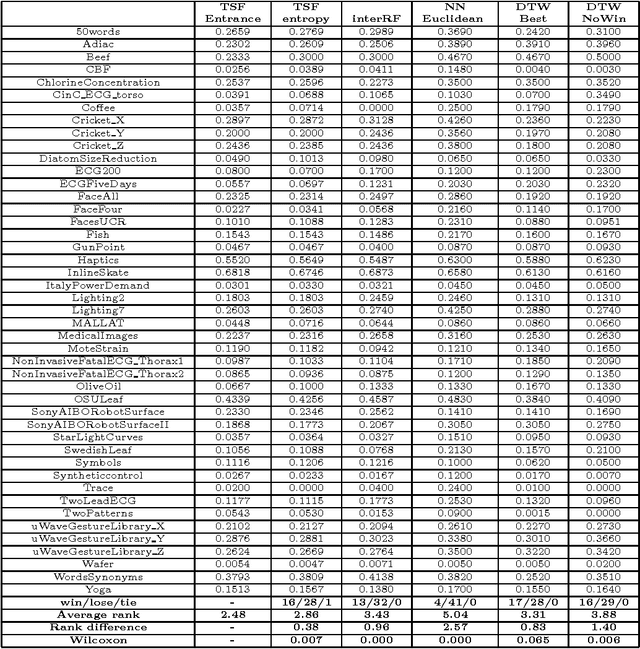
We propose a tree ensemble method, referred to as time series forest (TSF), for time series classification. TSF employs a combination of the entropy gain and a distance measure, referred to as the Entrance (entropy and distance) gain, for evaluating the splits. Experimental studies show that the Entrance gain criterion improves the accuracy of TSF. TSF randomly samples features at each tree node and has a computational complexity linear in the length of a time series and can be built using parallel computing techniques such as multi-core computing used here. The temporal importance curve is also proposed to capture the important temporal characteristics useful for classification. Experimental studies show that TSF using simple features such as mean, deviation and slope outperforms strong competitors such as one-nearest-neighbor classifiers with dynamic time warping, is computationally efficient, and can provide insights into the temporal characteristics.
Feature Selection via Regularized Trees
Mar 21, 2012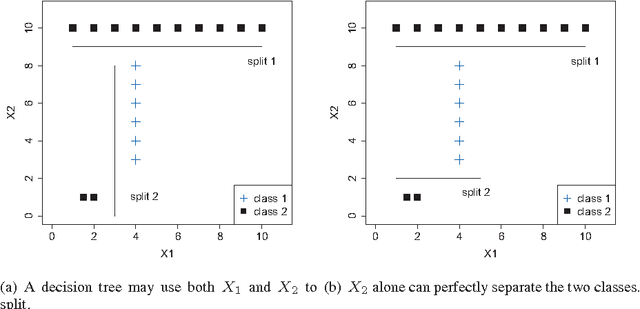
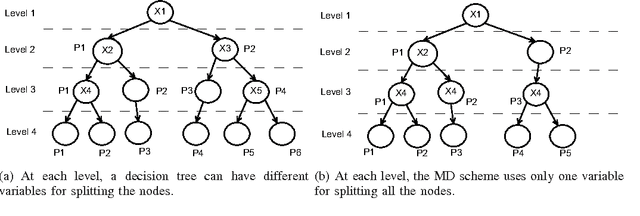
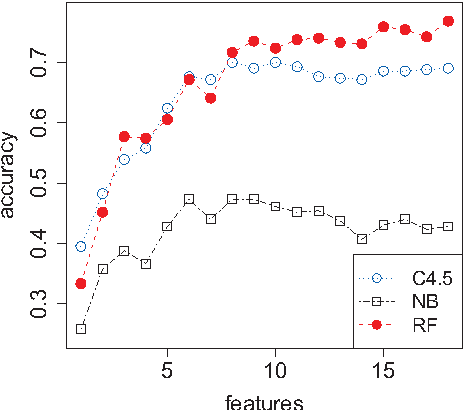
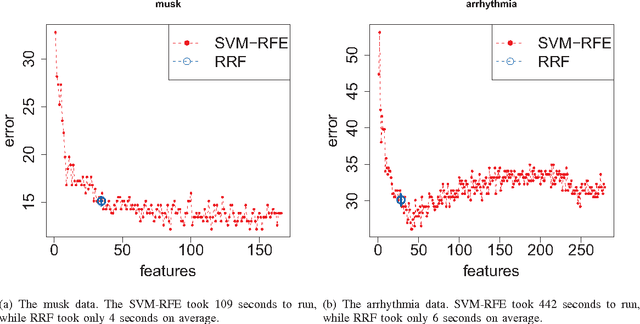
We propose a tree regularization framework, which enables many tree models to perform feature selection efficiently. The key idea of the regularization framework is to penalize selecting a new feature for splitting when its gain (e.g. information gain) is similar to the features used in previous splits. The regularization framework is applied on random forest and boosted trees here, and can be easily applied to other tree models. Experimental studies show that the regularized trees can select high-quality feature subsets with regard to both strong and weak classifiers. Because tree models can naturally deal with categorical and numerical variables, missing values, different scales between variables, interactions and nonlinearities etc., the tree regularization framework provides an effective and efficient feature selection solution for many practical problems.