 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPAD: Inverse Prompt for AI Detection -- A Robust and Explainable LLM-Generated Text Detector
Feb 21, 2025Large Language Models (LLMs) have attained human-level fluency in text generation, which complicates the distinguishing between human-written and LLM-generated texts. This increases the risk of misuse and highlights the need for reliable detectors. Yet, existing detectors exhibit poor robustness on out-of-distribution (OOD) data and attacked data, which is critical for real-world scenarios. Also, they struggle to provide explainable evidence to support their decisions, thus undermining the reliability. In light of these challenges, we propose IPAD (Inverse Prompt for AI Detection), a novel framework consisting of a Prompt Inverter that identifies predicted prompts that could have generated the input text, and a Distinguisher that examines how well the input texts align with the predicted prompts. We develop and examine two versions of Distinguishers. Empirical evaluations demonstrate that both Distinguishers perform significantly better than the baseline methods, with version2 outperforming baselines by 9.73% on in-distribution data (F1-score) and 12.65% on OOD data (AUROC). Furthermore, a user study is conducted to illustrate that IPAD enhances the AI detection trustworthiness by allowing users to directly examine the decision-making evidence, which provides interpretable support for its state-of-the-art detection results.
ComposeOn Academy: Transforming Melodic Ideas into Complete Compositions Integrating Music Learning
Feb 21, 2025

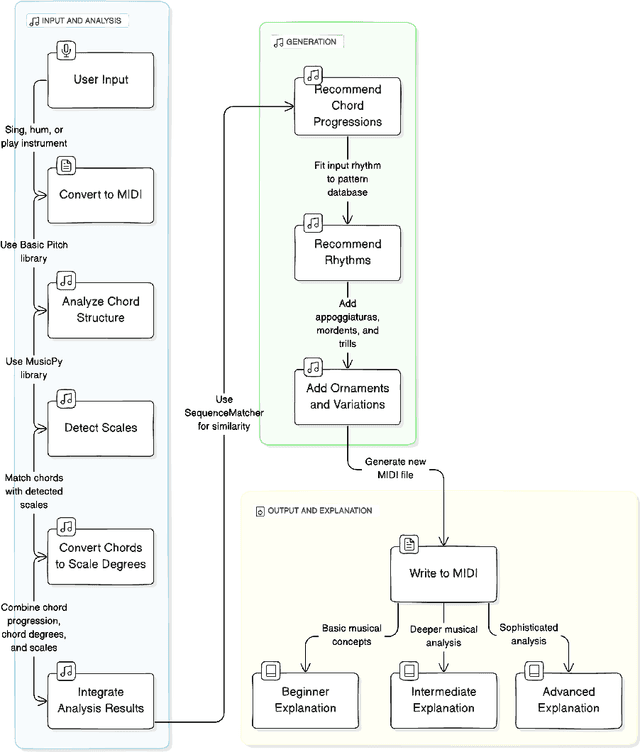
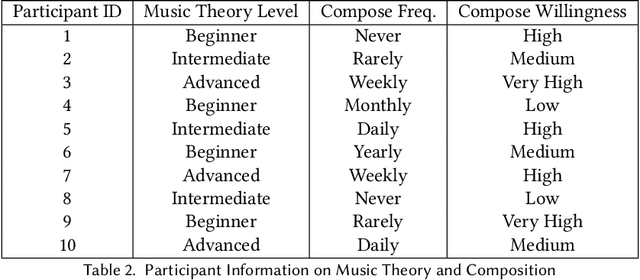
Music composition has long been recognized as a significant art form. However, existing digital audio workstations and music production software often present high entry barriers for users lacking formal musical training. To address this, we introduce ComposeOn, a music theory-based tool designed for users with limited musical knowledge. ComposeOn enables users to easily extend their melodic ideas into complete compositions and offers simple editing features. By integrating music theory, it explains music creation at beginner, intermediate, and advanced levels. Our user study (N=10) compared ComposeOn with the baseline method, Suno AI, demonstrating that ComposeOn provides a more accessible and enjoyable composing and learning experience for individuals with limited musical skills. ComposeOn bridges the gap between theory and practice, offering an innovative solution as both a composition aid and music education platform. The study also explores the differences between theory-based music creation and generative music, highlighting the former's advantages in personal expression and learning.