 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort Text Hashing Improved by Integrating Multi-Granularity Topics and Tags
Mar 10, 2015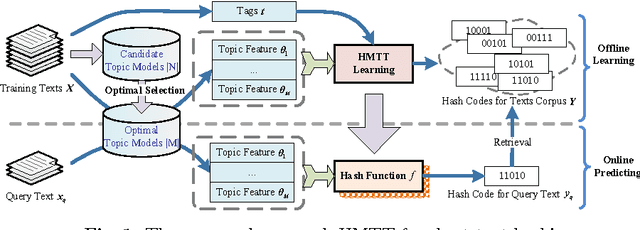


Due to computational and storage efficiencies of compact binary codes, hashing has been widely used for large-scale similarity search. Unfortunately, many existing hashing methods based on observed keyword features are not effective for short texts due to the sparseness and shortness. Recently, some researchers try to utilize latent topics of certain granularity to preserve semantic similarity in hash codes beyond keyword matching. However, topics of certain granularity are not adequate to represent the intrinsic semantic information. In this paper, we present a novel unified approach for short text Hashing using Multi-granularity Topics and Tags, dubbed HMTT. In particular, we propose a selection method to choose the optimal multi-granularity topics depending on the type of dataset, and design two distinct hashing strategies to incorporate multi-granularity topics. We also propose a simple and effective method to exploit tags to enhance the similarity of related texts. We carry out extensive experiments on one short text dataset as well as on one normal text dataset. The results demonstrate that our approach is effective and significantly outperforms baselines on several evaluation metrics.