 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Geometric Deficiency Elimination Algorithm for 3D Meshes
Mar 14, 2020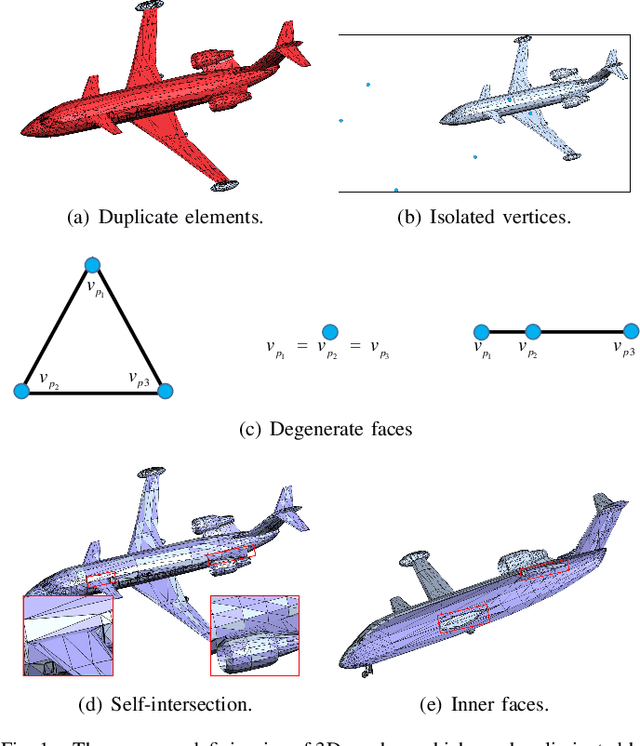
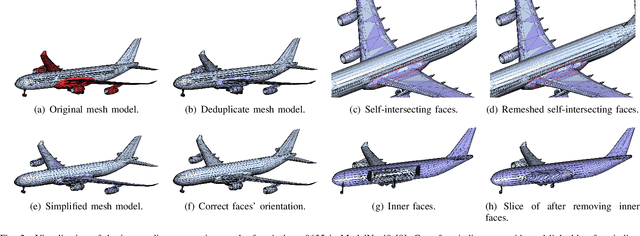

The 3D mesh is an important representation of geometric data. In the generation of mesh data, geometric deficiencies (e.g., duplicate elements, degenerate faces, isolated vertices, self-intersection, and inner faces) are unavoidable and may violate the topology structure of an object. In this paper, we propose an effective and efficient geometric deficiency elimination algorithm for 3D meshes. Specifically, duplicate elements can be eliminated by assessing the occurrence times of vertices or faces, degenerate faces can be removed according to the outer product of two edges; since isolated vertices do not appear in any face vertices, they can be deleted directly; self-intersecting faces are detected using an AABB tree and remeshed afterward; by simulating whether multiple random rays that shoot from a face can reach infinity, we can judge whether the surface is an inner face, then decide to delete it or not. Experiments on ModelNet40 dataset illustrate that our method can eliminate the deficiencies of the 3D mesh thoroughly.
One Point, One Object: Simultaneous 3D Object Segmentation and 6-DOF Pose Estimation
Dec 27, 2019



We propose a single-shot method for simultaneous 3D object segmentation and 6-DOF pose estimation in pure 3D point clouds scenes based on a consensus that \emph{one point only belongs to one object}, i.e., each point has the potential power to predict the 6-DOF pose of its corresponding object. Unlike the recently proposed methods of the similar task, which rely on 2D detectors to predict the projection of 3D corners of the 3D bounding boxes and the 6-DOF pose must be estimated by a PnP like spatial transformation method, ours is concise enough not to require additional spatial transformation between different dimensions. Due to the lack of training data for many objects, the recently proposed 2D detection methods try to generate training data by using rendering engine and achieve good results. However, rendering in 3D space along with 6-DOF is relatively difficult. Therefore, we propose an augmented reality technology to generate the training data in semi-virtual reality 3D space. The key component of our method is a multi-task CNN architecture that can simultaneously predicts the 3D object segmentation and 6-DOF pose estimation in pure 3D point clouds. For experimental evaluation, we generate expanded training data for two state-of-the-arts 3D object datasets \cite{PLCHF}\cite{TLINEMOD} by using Augmented Reality technology (AR). We evaluate our proposed method on the two datasets. The results show that our method can be well generalized into multiple scenarios and provide performance comparable to or better than the state-of-the-arts.